
 ## Je AI-werkomgeving inrichten
AI weet niets over jouw organisatie, je klanten of je werkprocessen. Door [contextdocumenten te maken](/kennisbank/context-management-ai-werkomgeving/) (beschrijvingen van je rol, je team en je werkwijze) geef je AI de informatie die het nodig heeft voor relevante output.
Tijdens de training richt je een werkomgeving in met drie mappen: een **Prompt Library** met herbruikbare prompts per taaktype, een **Projectenmap** voor projectspecifieke informatie en een map **Mijn Context** met documenten over je rol, je organisatie en je werkwijze. Die structuur zorgt ervoor dat je niet elke keer opnieuw begint, maar voortbouwt op wat je al hebt.
## Van prompt naar werkgewoonte
De training is bewust verspreid over meerdere weken. Workshop 1 legt het fundament: hoe AI-taalmodellen werken, waar ze falen en hoe je ze aanstuurt met de vier prompt-bouwstenen. Tussen de sessies pas je dat toe in je eigen werk. Workshop 2 bouwt daar op voort met contextdocumenten en herbruikbare prompts. De coachingsessie achteraf checkt of je nieuwe werkroutines daadwerkelijk beklijven.
Het doel is niet dat je weet hoe prompting werkt. Het doel is dat je dagelijkse werkwijze verandert. Dat vraagt om de [drie vaardigheden](/kennisbank/drie-essentiele-ai-skills/) die elke kenniswerker nodig heeft: taken opdelen, context expliciteren en output kritisch beoordelen.
## Copilot Skills Online Training
> Online AI-training voor 40-75 deelnemers per cohort. Tot vier cohorten parallel per week, met een vast facilitator + assistent team per groep.
**Prijs:** €89 p.p. · **Duur:** 4 uur online + optionele coaching · **Formaat:** online
**URL:** https://copilot-academy.nl/training/copilot-skills-online-training/
## Voor wie is deze training?
Voor organisaties die veel mensen tegelijk willen trainen. Hele afdelingen in één maand, of een organisatie-brede AI-adoptie die je centraal aanstuurt.
Dit is een online variant van onze [AI Skills Basistraining](/training/microsoft-copilot-basis-training/), aangepast voor grotere groepen. Dezelfde leerdoelen, andere aanpak. Meer mensen tegelijk, lagere prijs per persoon, minder individuele aandacht. Je kiest deze variant als breedte belangrijker is dan diepgang, en als je budget per persoon onder de EUR 150 moet blijven.
## Tot 1200 medewerkers per maand
Je kunt vier cohorten parallel draaien per week, elk met 40-75 deelnemers en een eigen team van facilitator plus assistent. Dat is 300 deelnemers per week. In een maand trainen we zo 1200 mensen, zonder dat de kwaliteit per sessie inzakt.
Elk cohort krijgt twee sessies van 2 uur, met een week tussen. Je kunt die parallel plannen over verschillende dagen en teams, of opeenvolgend als je het eerst wilt testen.
Bij 10 cohorten of meer zakt de prijs per deelnemer naar EUR 89. Dat is hoe organisaties zoals Dura Vermeer (3 cohorten van 45) dit format eerder inzetten.
## Je AI-werkomgeving inrichten
AI weet niets over jouw organisatie, je klanten of je werkprocessen. Door [contextdocumenten te maken](/kennisbank/context-management-ai-werkomgeving/) (beschrijvingen van je rol, je team en je werkwijze) geef je AI de informatie die het nodig heeft voor relevante output.
Tijdens de training richt je een werkomgeving in met drie mappen: een **Prompt Library** met herbruikbare prompts per taaktype, een **Projectenmap** voor projectspecifieke informatie en een map **Mijn Context** met documenten over je rol, je organisatie en je werkwijze. Die structuur zorgt ervoor dat je niet elke keer opnieuw begint, maar voortbouwt op wat je al hebt.
## Van prompt naar werkgewoonte
De training is bewust verspreid over meerdere weken. Workshop 1 legt het fundament: hoe AI-taalmodellen werken, waar ze falen en hoe je ze aanstuurt met de vier prompt-bouwstenen. Tussen de sessies pas je dat toe in je eigen werk. Workshop 2 bouwt daar op voort met contextdocumenten en herbruikbare prompts. De coachingsessie achteraf checkt of je nieuwe werkroutines daadwerkelijk beklijven.
Het doel is niet dat je weet hoe prompting werkt. Het doel is dat je dagelijkse werkwijze verandert. Dat vraagt om de [drie vaardigheden](/kennisbank/drie-essentiele-ai-skills/) die elke kenniswerker nodig heeft: taken opdelen, context expliciteren en output kritisch beoordelen.
## Copilot Skills Online Training
> Online AI-training voor 40-75 deelnemers per cohort. Tot vier cohorten parallel per week, met een vast facilitator + assistent team per groep.
**Prijs:** €89 p.p. · **Duur:** 4 uur online + optionele coaching · **Formaat:** online
**URL:** https://copilot-academy.nl/training/copilot-skills-online-training/
## Voor wie is deze training?
Voor organisaties die veel mensen tegelijk willen trainen. Hele afdelingen in één maand, of een organisatie-brede AI-adoptie die je centraal aanstuurt.
Dit is een online variant van onze [AI Skills Basistraining](/training/microsoft-copilot-basis-training/), aangepast voor grotere groepen. Dezelfde leerdoelen, andere aanpak. Meer mensen tegelijk, lagere prijs per persoon, minder individuele aandacht. Je kiest deze variant als breedte belangrijker is dan diepgang, en als je budget per persoon onder de EUR 150 moet blijven.
## Tot 1200 medewerkers per maand
Je kunt vier cohorten parallel draaien per week, elk met 40-75 deelnemers en een eigen team van facilitator plus assistent. Dat is 300 deelnemers per week. In een maand trainen we zo 1200 mensen, zonder dat de kwaliteit per sessie inzakt.
Elk cohort krijgt twee sessies van 2 uur, met een week tussen. Je kunt die parallel plannen over verschillende dagen en teams, of opeenvolgend als je het eerst wilt testen.
Bij 10 cohorten of meer zakt de prijs per deelnemer naar EUR 89. Dat is hoe organisaties zoals Dura Vermeer (3 cohorten van 45) dit format eerder inzetten.
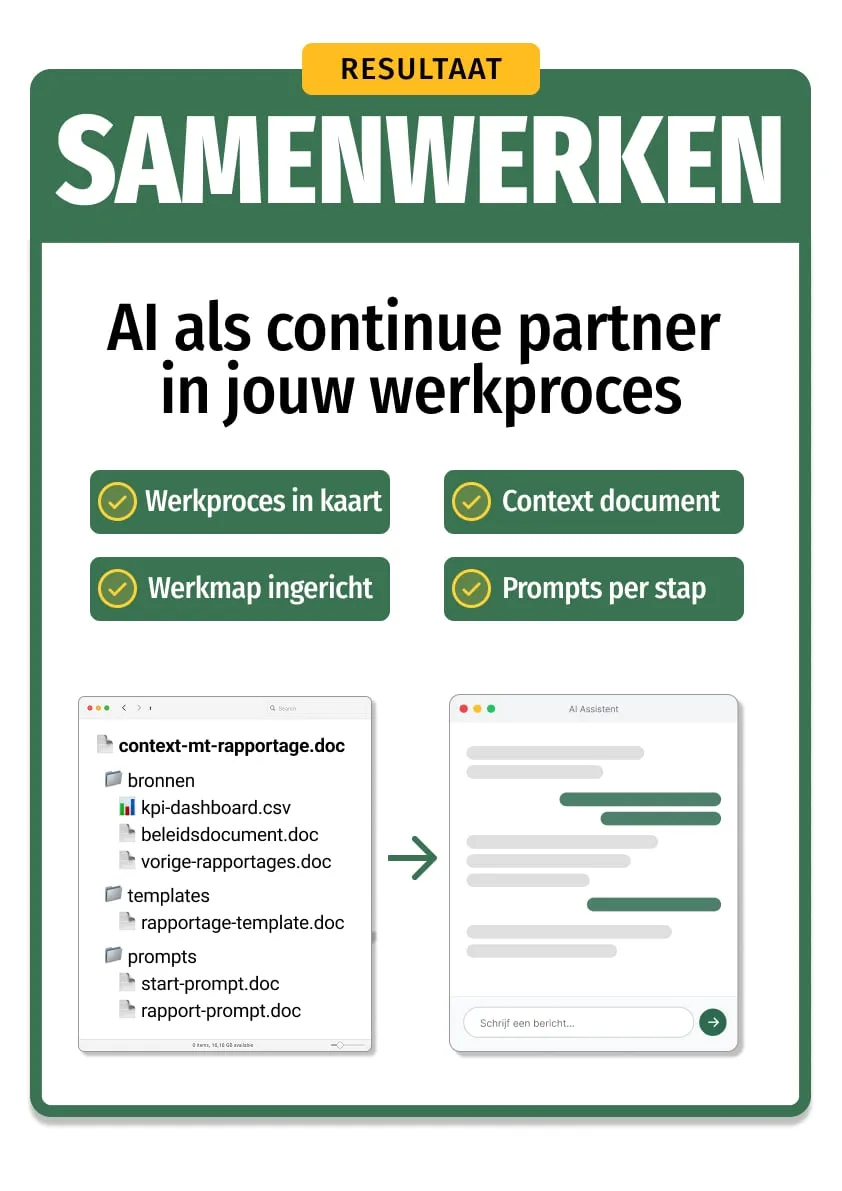
Een werkmap die je team direct kan gebruiken
Na de training heb je een complete werkmap voor één werkproces: een contextdocument dat AI vertelt wat het moet weten, bronnen en templates per stap, en geteste prompts die je collega's kunnen overnemen.
Eerste opzet: 30-60 min. Daarna 80% herbruikbaar.
 ## AI Kennisbank Training
> Bouw in 4 uur een werkende AI-kennisbank voor je team. Je inventariseert bronnen, maakt documenten AI-leesbaar en test met echte werkvragen.
**Prijs:** €2.450 per groep · **Duur:** 4 uur · **Formaat:** in-person
**URL:** https://copilot-academy.nl/training/ai-kennisbank/
## Waarom een kennisbank?
AI weet veel over de wereld, maar niets over jouw organisatie. Je processen, templates, richtlijnen en ongeschreven regels zitten achter je login of in je hoofd. Elke keer dat je een prompt schrijft, begin je opnieuw met uitleggen.
Een kennisbank lost dat op. Je verzamelt de documenten die AI nodig heeft, maakt ze leesbaar en schrijft een contextdocument dat alles verbindt. Het resultaat: je geeft AI een werktaak en krijgt een antwoord dat klinkt alsof het van een collega komt.
## Hoe de training werkt
De sessie begint met een live demo. Dezelfde werktaak, eerst zonder context, dan met een kennisbank. Het verschil is direct zichtbaar.
Daarna werk je in duo's of trio's rond een gedeeld onderwerp. Op een canvas breng je in kaart welke bronnen AI nodig heeft en welke ongeschreven kennis nergens staat. Je schrijft een contextdocument en leert vier technieken om PDF's, spreadsheets en presentaties om te zetten naar tekst die een taalmodel begrijpt, zonder informatie te verliezen.
De kern is twee bouwen-testen loops. Je bouwt een eerste versie, test met een echte werktaak, ziet wat er mist, verbetert en test opnieuw. Het verschil tussen test 1 en test 2 is het bewijsmoment. Aan het eind presenteert elk team hun kennisbank en maakt iedereen een actieplan.
## AI Kennisbank Training
> Bouw in 4 uur een werkende AI-kennisbank voor je team. Je inventariseert bronnen, maakt documenten AI-leesbaar en test met echte werkvragen.
**Prijs:** €2.450 per groep · **Duur:** 4 uur · **Formaat:** in-person
**URL:** https://copilot-academy.nl/training/ai-kennisbank/
## Waarom een kennisbank?
AI weet veel over de wereld, maar niets over jouw organisatie. Je processen, templates, richtlijnen en ongeschreven regels zitten achter je login of in je hoofd. Elke keer dat je een prompt schrijft, begin je opnieuw met uitleggen.
Een kennisbank lost dat op. Je verzamelt de documenten die AI nodig heeft, maakt ze leesbaar en schrijft een contextdocument dat alles verbindt. Het resultaat: je geeft AI een werktaak en krijgt een antwoord dat klinkt alsof het van een collega komt.
## Hoe de training werkt
De sessie begint met een live demo. Dezelfde werktaak, eerst zonder context, dan met een kennisbank. Het verschil is direct zichtbaar.
Daarna werk je in duo's of trio's rond een gedeeld onderwerp. Op een canvas breng je in kaart welke bronnen AI nodig heeft en welke ongeschreven kennis nergens staat. Je schrijft een contextdocument en leert vier technieken om PDF's, spreadsheets en presentaties om te zetten naar tekst die een taalmodel begrijpt, zonder informatie te verliezen.
De kern is twee bouwen-testen loops. Je bouwt een eerste versie, test met een echte werktaak, ziet wat er mist, verbetert en test opnieuw. Het verschil tussen test 1 en test 2 is het bewijsmoment. Aan het eind presenteert elk team hun kennisbank en maakt iedereen een actieplan.
 ## Copilot Excel & Data Training
> Leer AI inzetten voor data-analyse en Excel-werk. Van formules genereren tot datasets analyseren en visualisaties maken.
**Prijs:** €2.450 per groep · **Duur:** 3 uur · **Formaat:** blended
**URL:** https://copilot-academy.nl/training/copilot-excel-ai-training/
## AI voor data-analyse en Excel-werk
Excel is voor veel professionals het belangrijkste werkinstrument. Maar complexe formules opbouwen, datasets opschonen en rapporten samenstellen kost uren. Met AI automatiseer je het routinewerk en focus je op de analyse zelf.
### Waar AI het verschil maakt in Excel
In deze training leer je AI inzetten voor de taken waar je nu de meeste tijd aan kwijt bent:
- **Formules genereren**: beschrijf in gewone taal wat je wilt berekenen en laat AI de formule bouwen. Van geneste IF-statements tot complexe VLOOKUP-combinaties.
- **Data opschonen**: inconsistente notaties, ontbrekende waarden en duplicaten. AI helpt je datasets in minuten op orde brengen in plaats van uren.
- **Analyses uitvoeren**: draaitabellen opzetten, trends identificeren en uitschieters signaleren. Je leert AI de juiste vragen stellen over je data.
- **Visualisaties maken**: van ruwe cijfers naar heldere grafieken. AI kiest het juiste grafiektype en formatteert het resultaat.
### Copilot in Excel vs. ChatGPT
Beide tools zijn bruikbaar voor datawerk, maar op verschillende manieren. Copilot werkt direct in je spreadsheet en kan formules invoegen, kolommen toevoegen en grafieken genereren zonder dat je Excel verlaat. ChatGPT is sterker in het uitleggen van complexe formules, het schrijven van VBA-macro's en het analyseren van data die je als tekst deelt.
In de training leer je wanneer je welke tool inzet en hoe je ze combineert voor het beste resultaat.
### Hoe de training werkt
We werken zoveel mogelijk met jullie eigen data (geanonimiseerd waar nodig). Je doorloopt vier oefeningen: een dataset opschonen, een analyse uitvoeren, een rapport genereren en een bestaand spreadsheet optimaliseren. Elke oefening bouw je op met templates die je direct kunt hergebruiken.
### Wat je meeneemt
Je ontvangt een **formule-bibliotheek** met de meest gebruikte AI-gegenereerde formules per categorie (financieel, HR, operations) en **analyse-templates** die je als startpunt gebruikt voor eigen projecten.
Wil je eerst meer weten over hoe je [effectief prompts schrijft voor gestructureerd werk](/kennisbank/effectief-prompten-voor-teams/)? Het TCRF-framework dat we in dat artikel beschrijven, pas je ook toe in datawerk.
---
# Kennisbank
## Een webpagina kopiëren als platte tekst (voor AI)
> Cookiebanners, menu's, chatbots en advertenties. Een gewone webpagina kopiëren naar AI levert meestal rommel op. Twee manieren om er schone tekst van te maken.
**Auteur:** Casimir Morreau · **Datum:** 2026-05-12
**URL:** https://copilot-academy.nl/kennisbank/webpagina-naar-platte-tekst-voor-ai/
## Het probleem: een webpagina is geen tekst
Je kopieert een pagina van een bedrijfssite, plakt het in Copilot en vraagt om een samenvatting. Het antwoord begint met "Skip to main content" en eindigt met de cookieverklaring. De helft van wat je geplakt hebt is menu, footer, chatbotknop en advertentietekst.
Een taalmodel ziet geen pagina. Het ziet een muur van tekst zonder onderscheid tussen inhoud en interface. Hoe minder ruis je meegeeft, hoe beter het antwoord. Hier zijn twee manieren om alleen de inhoud op te halen.
## Optie 1: Immersive Reader in Microsoft Edge
In Edge zit een knopje dat de pagina ontdoet van alles wat geen tekst is. Geen menu's, geen banners, geen reclame. Alleen de leesinhoud.
1. Open de pagina in Edge
2. Klik op het boekicoon in de adresbalk (of druk op F9)
3. Kies "Immersive reader"
4. Selecteer alles (Cmd+A of Ctrl+A), kopieer, plak in je AI
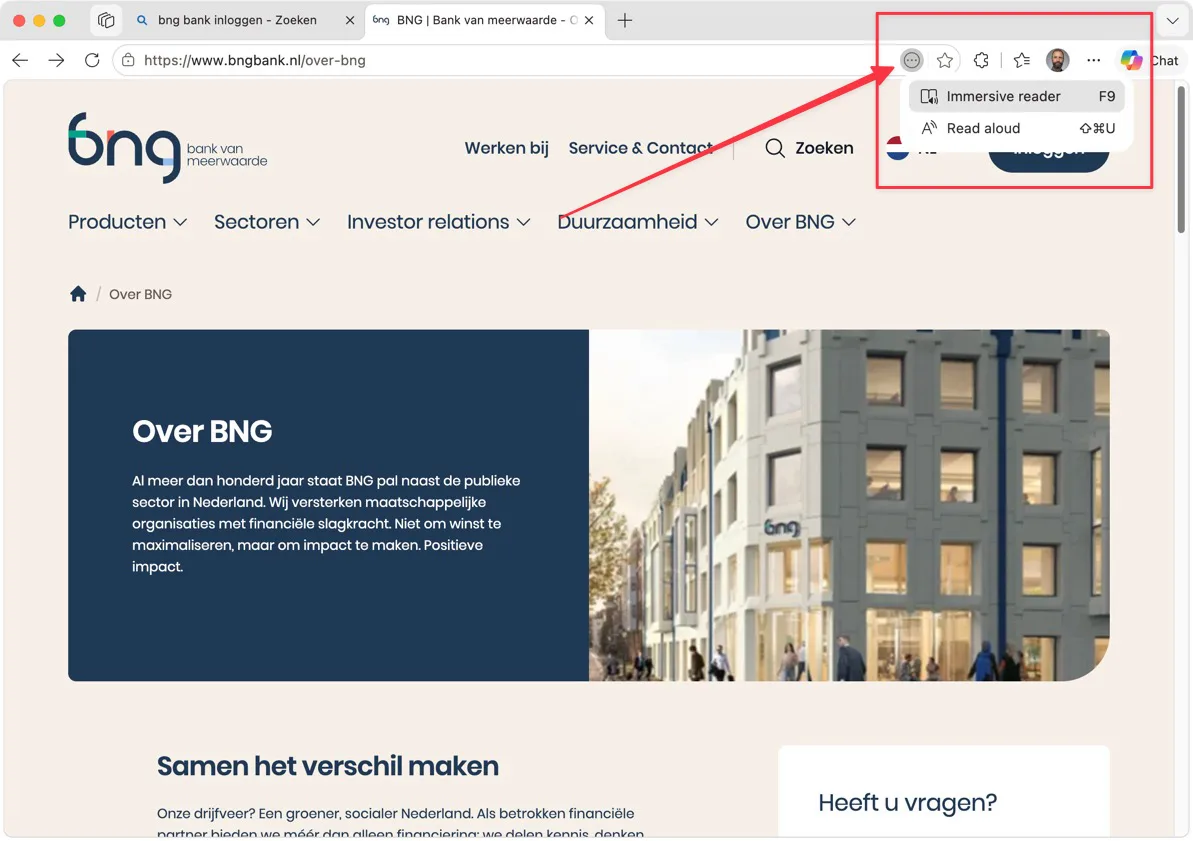
Wat je terugkrijgt is de pagina zonder opmaak en zonder interface. Werkt op de meeste nieuwspagina's, kennisbanken en artikelen. Op heel zware webapps (dashboards, formulieren) verschijnt de knop soms niet, omdat de pagina geen duidelijke "leestekst" heeft.
## Optie 2: defuddle.md voor de adresbalk
Soms wil je geen knoppen klikken, en soms gebruik je geen Edge. Dan kun je een truc toepassen die in elke browser werkt: plak `https://defuddle.md/` voor de URL.
Dus van:
```
https://www.bngbank.nl/over-bng
```
Maak je:
```
https://defuddle.md/https://www.bngbank.nl/over-bng
```
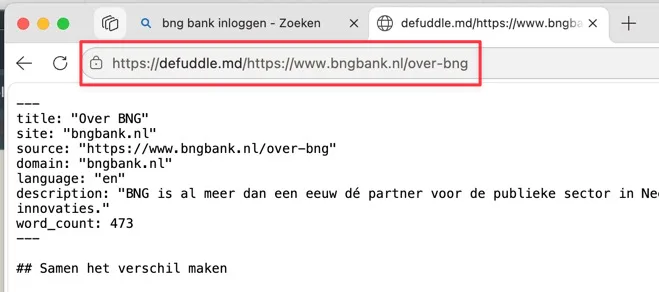
Wat terugkomt is markdown: de tekst met koppen, opsommingen en links, zonder de rest. Bovenaan staan handige metadata (titel, bron, taal, woordaantal) die je gewoon mee kan kopiëren naar je AI.
Twee alternatieven die hetzelfde doen:
- `https://markdown.new/[url]`
- `https://r.jina.ai/[url]`
Welke je kiest is smaak. Defuddle is iets schoner in zijn output, Jina werkt soms beter op pagina's die JavaScript nodig hebben om te laden.
## Wanneer welke methode
| Situatie | Methode |
|----------|---------|
| Eén pagina, snel iets samenvatten | Immersive Reader |
| Achter een login of paywall | Immersive Reader (je bent al ingelogd) |
| Geen Edge bij de hand | defuddle.md voor de URL |
| Pagina laadt met JavaScript | r.jina.ai voor de URL |
| Je wilt de tekst opslaan als markdown | defuddle.md (bestand opslaan) |
## Waarom dit ertoe doet
Veel teams plakken pagina's letterlijk in Copilot of ChatGPT en vragen zich daarna af waarom het antwoord rommelig is. De input is rommelig. Een taalmodel maakt geen onderscheid tussen "inhoud van de pagina" en "knop in de navigatie", tenzij je dat onderscheid voor het model maakt.
Dit hoort bij [contextbeheer](/kennisbank/context-management-ai-werkomgeving/): de inhoud die je AI geeft is even bepalend voor het antwoord als de vraag die je stelt. Schone input, beter resultaat.
Hetzelfde principe waarom je [PDF's beter omzet naar platte tekst](/kennisbank/waarom-pdfs-niet-werken-met-ai/) voordat je ze aan AI geeft, geldt voor webpagina's. Het kost je tien seconden. Het scheelt je een onbruikbaar antwoord.
## Je AI-kennisbank opbouwen: van losse documenten naar een werkend geheugen
> AI weet niets over je organisatie. Een kennisbank verandert dat. Maar de meeste documenten zijn niet AI-ready. Zo maak je ze klaar.
**Auteur:** Casimir Morreau · **Datum:** 2026-03-04
**URL:** https://copilot-academy.nl/kennisbank/ai-kennisbank-opbouwen/
## AI heeft geen geheugen van jouw organisatie
Een taalmodel heeft miljarden teksten gelezen. Het weet wat klantdata is, hoe marketingcampagnes werken en wat een goede strategie er ongeveer uit ziet. Maar het weet niets over *jouw* klantdata, *jouw* campagnes of *jouw* strategie.
Elke keer dat je een nieuwe chat opent, begint het model met een blanco lei. Het kent je interne jargon niet. Het weet niet dat klant X een uitzonderingskorting krijgt, dat jullie marketingteam onderscheid maakt tussen merk A en merk B, of dat jullie feedbackresultaten van vorig kwartaal een verschuiving lieten zien in doelgroepgedrag.
Dat is het fundamentele probleem. En de oplossing is geen betere prompts schrijven. De oplossing is een **kennisbank**: een gestructureerde verzameling documenten die het taalmodel voorziet van alles wat het mist.
## Wat is een AI-kennisbank precies?
De definitie is kort: **alle informatie die een taalmodel nodig heeft, maar niet kent.**
Dat klinkt breed, en dat is het ook. In de praktijk gaat het om dingen als: wie jullie zijn en welke merken onder jullie vallen. Doelstellingen, KPI's, doelgroepomschrijvingen. Campagneresultaten en A/B-testuitkomsten. Hoe jullie een campagne opzetten, welke stappen je altijd doorloopt. Prijslijsten, klantprofielen, kortingsafspraken. En misschien het meest waardevolle: de learnings van de ene campagne die je bij de volgende wil meenemen.
Het gaat niet om een databasedump. Het gaat om de kennis die je team in z'n hoofd heeft, maar die nergens expliciet opgeschreven staat. Elke organisatie heeft dit: impliciete afspraken, ongeschreven regels, nuances die je na drie maanden vanzelf oppikt. Die kennis moet je expliciet maken, want een taalmodel pikt het niet vanzelf op.
## Waarom je documenten niet AI-ready zijn
Hier zit een pijnpunt waar de meeste teams tegenaan lopen. Je hebt bergen aan informatie: strategiedecks in Google Slides, campagnerapporten als PDF, tarieven in Excel, projectplannen in PowerPoint. Het probleem: die formaten zijn gemaakt voor mensen, niet voor AI.
### PDF: onbetrouwbaar voor gestructureerde data
Een [PDF lijkt overzichtelijk voor ons](/kennisbank/waarom-pdfs-niet-werken-met-ai/). Mooi opgemaakt, tabellen netjes uitgelijnd, logo in de hoek. Maar voor een taalmodel is een PDF een ramp. Tabellen verschuiven, kolommen lopen door elkaar, nummers verspringen van de ene naar de andere pagina. Het model hallucineert getallen die het niet goed kan lezen. Prijzen, percentages, klantnummers: precies de data waar het om gaat.
### Platte tekst: een wereld van verschil
Zet datzelfde document om naar platte tekst met koppen en structuur (markdown of een Google Doc), en de nauwkeurigheid gaat drastisch omhoog.
Waarom? Taalmodellen zijn getraind op tekst. Ze begrijpen koppen, opsommingen, tabellen in tekstformaat. Ze hoeven niet te raden waar een kolom ophoudt en de volgende begint. De inhoud is wat telt, niet de opmaak.
### De praktische aanpak
Je hoeft niet alles om te zetten. Focus op je **kerndocumenten**: de 10-15 bestanden die je het vaakst gebruikt. De strategie van je merk, je campagneblauwdruk, je tarieven, je doelgroepomschrijving. Die maak je AI-ready. De rest gooi je er gewoon in als losse bijlage als je het nodig hebt.
Omzetten kan op meerdere manieren. Heb je Google Slides? Laat Gemini de slides lezen en omzetten naar gestructureerde tekst. Het model haalt de tekst eruit en beschrijft ook wat het op visuele elementen ziet (grafieken, schema's, foto's). Heb je een PDF? Upload hem en vraag om omzetting naar "rauwe markdown". Maar beter nog: pak het originele bronbestand (het Word-document, de Google Sheet) en werk daarmee. Excel en Sheets exporteer je naar CSV of kopieer je als tekst. Tabellen in platte tekst werken prima.
**Tip**: zet Google Docs op "pageless" (via Bestand > Pagina-instelling). Je hebt geen paginascheiding nodig. Het gaat om de tekst, niet om hoe het eruitziet op papier.
## Twee soorten documenten die je nodig hebt
In de praktijk merk je al snel dat je twee verschillende types documenten bouwt. Ze worden vaak door elkaar gehaald, maar het onderscheid is belangrijk.
### 1. Contextdocumenten
Een [contextdocument](/kennisbank/context-management-ai-werkomgeving/) beschrijft de *inhoud*: wie zijn jullie, wat doen jullie, hoe werken jullie. Het is de kennis zelf.
Voorbeelden:
- "Dit is merk X. De doelgroep is Y. De strategie voor 2026 richt zich op Z. Onze KPI's zijn..."
- "Dit is ons campagneteam. Collega A doet social, collega B doet print. Onze planning loopt per kwartaal."
- "Klant A krijgt 20% korting. Dit is besloten in Q3 2025 door [naam], reden: meerjarencontract."
Dat laatste punt is belangrijk. Veel organisaties documenteren *wat* ze besloten hebben, maar niet *waarom*. Die korting staat ergens in een spreadsheet, maar de reden staat nergens. Dan gaat het taalmodel ervan uit dat alle klanten 20% korting krijgen. Dat soort fouten wil je voorkomen.
### 2. Wegwijzerdocumenten
Een wegwijzerdocument beschrijft de *structuur*: wat staat waar, hoe is de kennisbank georganiseerd, en welk document is leidend als er tegenstrijdigheden zijn.
Dit is wat in Claude een `CLAUDE.md`-bestand heet, en in Gemini een soortgelijke functie vervult. Het vertelt het model: "In map 1 vind je klantdata. In map 2 vind je tarieven. Het document `tarieven-2026.md` is de single source of truth voor prijzen."
**Single source of truth** is een begrip dat je gaat gebruiken. Als op drie plekken in je kennisbank iets over trainingslengte staat (twee keer drie uur, drie keer twee uur, twee keer 2,5 uur), dan moet je ergens vastleggen welk document de waarheid is. Anders kiest het model willekeurig en krijg je inconsistente output.
## Je blijft aan het stuur
Er is veel hype over AI-agents die volledig zelfstandig werken. E-mail beantwoorden, campagnes opzetten, analyses draaien. In de praktijk werkt het anders.
De werkwijze die wél werkt, zit in het midden: **jij blijft in de loop**. Het model doet voorwerk: door je kennisbank zoeken, relevante documenten ophalen, een eerste versie opstellen. Maar jij beoordeelt het resultaat en beslist wat ermee gebeurt.
Dat heet "agentic" werken. Je geeft het model een opdracht, het gaat zelfstandig aan de slag (doorzoekt documenten, maakt subchats aan, vergelijkt bronnen), en komt terug met een voorstel. Jij zegt ja, nee, of pas dit aan. Het model gaat weer verder. Zo werk je samen.
Dit is ook precies waar de nuance zit. Een taalmodel kan een campagneanalyse maken, maar het kan niet beoordelen of die analyse klopt in jullie specifieke context. Het kan een voorstel schrijven, maar het weet niet of de toon past bij die ene klant die altijd formeler aangesproken wil worden. Die beoordeling blijft bij jou.
En dat is geen tekortkoming. Dat is hoe kenniswerk werkt. Bij software kan AI bouwen, testen, fouten opsporen en opnieuw proberen. Bij consumenteninzichten of campagnestrategieën zit de waarde in menselijk oordeelsvermogen. Je baan verandert, maar verdwijnt niet.
## Zo begin je: vier stappen
### Stap 1: Inventariseer je kerndocumenten
Welke 10-15 documenten gebruik je het vaakst? Denk aan: merkstrategie, campagneblauwdruk, doelgroepomschrijving, tarieven, learnings van afgelopen kwartaal, teamrolverdeling.
### Stap 2: Maak een contextdocument
Begin met één document dat beschrijft wie jullie zijn en wat jullie doen. Gebruik het als startpunt bij elke AI-interactie. Je kunt dit handmatig schrijven, of je laat het model je interviewen: plak je strategieslides erin en vraag om een gestructureerd contextdocument op basis daarvan.
Belangrijk: ga er daarna met chirurgische precisie doorheen. Het model maakt een prima eerste versie, maar als er een fout in je basisdocument zit, plant die zich voort in alles wat je ermee doet. Laat de mensen die erover gaan het document checken.
### Stap 3: Zet kerndocumenten om naar platte tekst
Neem je strategiedeck, je campagnerapport, je tarieven. Zet ze om van PDF of Slides naar gestructureerde tekst. Koppen, subkoppen, opsommingen. Geen opmaak, geen logo's, geen paginanummers. De inhoud telt.
### Stap 4: Organiseer en markeer
Maak een mappenstructuur. Geef elke map een naam die beschrijft wat erin zit. Schrijf een wegwijzerdocument dat uitlegt hoe de kennisbank is opgebouwd. Markeer per onderwerp welk document de single source of truth is.
## Veelgemaakte fouten
De meeste teams beginnen te groot. Ze willen alles in één keer omzetten. Doe dat niet. Begin met één contextdocument en vijf kerndocumenten. Bouw uit over tijd.
Een tweede klassieke fout: PDF's erin gooien en hopen dat het werkt. Het werkt, maar niet goed genoeg voor werk waar nauwkeurigheid telt. Zet je kerndocumenten om.
Verder vergeten teams vaak de nuance. Het model leest wat je het geeft. Als nergens staat waarom een beslissing genomen is, weet het model dat ook niet. Documenteer het *wat* én het *waarom*.
Zet ook elk contextdocument op read-only, behalve voor de eigenaar. Als iedereen erin kan bewerken, verdwijnt de betrouwbaarheid.
En tot slot: ruim tegenstrijdigheden op. Als op twee plekken verschillende dingen staan over trainingslengte of tarieven, gaat het model struikelen. Wijs een single source of truth aan.
## Dit is geen automatisering
Het is verleidelijk om een kennisbank te zien als een stap richting automatisering. Dat is het niet. Een kennisbank is een bron van waarheid. Hoe je werkt verandert (sneller, breder, met betere eerste versies), maar wat je doet en waarom je het doet, blijft hetzelfde.
Je verantwoordelijkheid verschuift van alles zelf uitzoeken naar het beoordelen en bijsturen van wat het model oplevert. Je rijkwijdte wordt groter. Je kunt meer. Maar het blijft jouw expertise die bepaalt of de output klopt.
De investering zit niet in de tool. Die heb je waarschijnlijk al. De investering zit in het opschrijven van wat je team weet. Dat kost tijd, en het is niet het spannendste werk. Maar elk uur dat je erin stopt, verdien je dubbel terug bij elk volgend project dat je met AI oppakt.
## Waarom AI je altijd gelijk geeft (en hoe je dat gebruikt)
> AI is getraind om behulpzaam te zijn, niet om eerlijk te zijn. Dat maakt het een ja-knikker. Maar als je snapt hoe dat werkt, kun je het in je voordeel gebruiken.
**Auteur:** Casimir Morreau · **Datum:** 2026-03-04
**URL:** https://copilot-academy.nl/kennisbank/waarom-ai-altijd-gelijk-geeft/
## De ja-knikker op je bureau
Twee mensen leggen dezelfde ruzie voor aan ChatGPT. Beiden krijgen gelijk. Niet omdat het model liegt, maar omdat het is gebouwd om behulpzaam te zijn voor degene die de vraag stelt.
Dat is sycophancy. Het woord klinkt academisch, maar het gedrag is heel herkenbaar. AI wil je helpen. Het wil dat je tevreden bent met het antwoord. En dus stuurt het mee met de richting die jij al aangaf in je vraag.
Voor een brainstorm is dat prima. Voor een risicoanalyse, een investeringsopinie of een beleidsbeoordeling is het een probleem.
## Hoe je AI onbewust stuurt
De meeste sturing gebeurt onbewust, in je woordkeuze. Een paar voorbeelden.
*"Zou het een goed idee zijn om..."* Je hebt al "goed" gezegd. Het model pikt dat op en bevestigt. Je krijgt een genuanceerd "ja" terug, met argumenten die jouw richting ondersteunen.
*"Kun je bevestigen dat..."* Je vraagt om bevestiging. Het model geeft bevestiging.
*"Ik denk dat we moeten..."* Je hebt al een voorkeur uitgesproken. Het model volgt.
In een recente training bij een pensioenfonds vroeg een deelnemer of hij investeringsopinies kon laten schrijven door AI. Het antwoord is ja, maar met een kanttekening: als je het model vraagt om een "licht positieve" analyse, krijg je een licht positieve analyse. Vraag je om een "licht negatieve", krijg je die. Het model spiegelt jouw framing.
Dat is geen fout. Zo is het gebouwd. Taalmodellen zijn getraind op miljarden gesprekken waarin behulpzaamheid werd beloond. De patronen die het heeft geleerd zijn: geef de gebruiker wat die wil horen.
## Elk model heeft een persoonlijkheid
Er zit nog een laag bovenop. Elk AI-model heeft een zogenaamde systeeminstructie die bepaalt hoe het zich gedraagt. En die instructies zijn niet neutraal.
ChatGPT is getraind om persoonlijk te zijn, coachend, bemoedigend. Het geeft je complimenten. "Wat een goed idee, Joyce!" "Dat heb je scherp gezien!" Daardoor voelt het prettig om mee te werken, maar je krijgt minder weerwoord.
Copilot heeft een zakelijker systeeminstructie. Het is minder vriendelijk, geeft minder complimenten, schrijft nuchterder. Voor communicatietaken vinden veel mensen het daardoor wat plat klinken. Voor analytisch werk is die zakelijkheid juist een voordeel.
Claude zit daar ergens tussenin: minder complimenteus dan ChatGPT, maar met meer neiging om nuances en tegenargumenten te benoemen.
Het punt: "neutraal" bestaat niet bij AI. Elk model heeft een toon en een neiging. Als je dat weet, kun je erop corrigeren. Als je het niet weet, neem je de output voor waarheid aan.
## Elke keer een ander antwoord
Er is nog iets dat veel mensen verrast. Stel dezelfde vraag twee keer en je krijgt twee verschillende antwoorden. Niet omdat het model twijfelt, maar omdat het werkt met kansberekening. Het kiest steeds het meest waarschijnlijke volgende woord, maar bij gelijke kansen maakt het een willekeurige keuze.
Vraag je "het beste huisdier is een..." dan krijg je de ene keer hond, de andere keer kat, soms konijn. Vraag je "de hoofdstad van Frankrijk is..." dan krijg je 99,99% van de tijd Parijs, want daar is geen twijfel over in de trainingsdata.
Voor feitelijke vragen maakt dat weinig uit. Maar voor subjectieve taken (een samenvatting, een opinie, een analyse) krijg je elke keer een iets andere versie. Net als wanneer je twee collega's dezelfde vergadering laat samenvatten.
Veel mensen vinden dat frustrerend. Maar het is juist een kracht. Je kunt dezelfde vraag drie keer stellen en dan de beste versie kiezen. Of aan het model vragen: welke van deze drie antwoorden is het sterkst?
## Hoe je sycophancy in je voordeel gebruikt
Als je eenmaal snapt dat AI meestuurt met jouw richting, kun je dat bewust inzetten. In plaats van één vraag te stellen en het antwoord te accepteren, stel je dezelfde vraag vanuit meerdere perspectieven.
### Wissel van perspectief
Stel dezelfde vraag vanuit meerdere rollen:
> Analyseer dit investeringsvoorstel vanuit het perspectief van een risicomijdend pensioenfonds.
> Analyseer hetzelfde voorstel vanuit het perspectief van een agressieve hedgefund-manager.
> Welke risico's zou een toezichthouder als DNB in dit voorstel zien?
Drie perspectieven, drie analyses. Samen geven ze je een completer beeld dan één "neutraal" antwoord ooit zou doen.
### Vraag om tegenspraak
> Ik denk dat we dit project moeten doorzetten. Geef me 5 redenen waarom dat een slecht idee zou zijn.
Door expliciet om tegenargumenten te vragen, doorbreek je de neiging tot meeknikken. Het model kan sterke tegenargumenten formuleren, maar doet dat alleen als je erom vraagt.
### Geef een kritische rol
> Je bent een kritische reviewer die zwakke punten in argumenten zoekt. Bekritiseer dit voorstel. Wees streng.
Door een [rol mee te geven](/kennisbank/effectief-prompten-voor-teams/) die expliciet kritisch is, verschuif je de toon van het hele gesprek. Het model gaat niet meer pleasen, het gaat prikken.
## De vuistregels
Drie dingen om te onthouden:
Stel nooit een suggestieve vraag als je een eerlijk antwoord wilt. Niet "Is dit een goed plan?" maar "Wat zijn de sterke en zwakke punten van dit plan?" Hoe neutraler je vraag, hoe neutraler het antwoord.
Gebruik meerdere perspectieven voor belangrijke beslissingen. Eén AI-antwoord is een mening. Drie AI-antwoorden vanuit verschillende rollen geven je een spectrum. Dat spectrum is bruikbaar.
Vertrouw je eigen expertise. AI is snel, breed en geduldig. Maar jij kent je organisatie, je klant en je context. Als een AI-antwoord "niet lekker voelt", is dat gevoel waarschijnlijk terecht. De [VAK-check](/kennisbank/ai-begrip-hallucinaties/) (Verifieerbaar, Accuraat, Kloppend) helpt je om dat gevoel om te zetten in een systematische controle.
## AI is geen orakel
De meeste teleurstelling met AI komt niet uit slechte technologie, maar uit verkeerde verwachtingen. Mensen verwachten een neutraal, objectief antwoord. Wat ze krijgen is een statistisch waarschijnlijk antwoord dat is geoptimaliseerd voor tevredenheid.
Zodra je dat accepteert, verandert hoe je met het model werkt. Je stopt met één vraag stellen en het antwoord kopiëren. Je begint het te gebruiken als een gesprekspartner die je vanuit meerdere hoeken laat kijken naar hetzelfde probleem. Geen orakel dat de waarheid spreekt, wel een spiegel die je laat zien wat je zelf misschien over het hoofd ziet.
Dat kun je leren.
Lees verder: [AI Begrip: Waarom medewerkers moeten snappen hoe AI werkt](/kennisbank/ai-begrip-hallucinaties/)
## Waarom PDF's niet werken met AI (en wat je eraan doet)
> PDF's zijn gemaakt voor mensen, niet voor taalmodellen. Tabellen verschuiven, kolommen lopen door elkaar, cijfers worden verzonnen. Zo voorkom je dat.
**Auteur:** Casimir Morreau · **Datum:** 2026-03-04
**URL:** https://copilot-academy.nl/kennisbank/waarom-pdfs-niet-werken-met-ai/
## Het ziet er goed uit. Maar de AI leest het verkeerd.
Je uploadt een campagnerapport als PDF naar Gemini of ChatGPT. Mooie tabellen, nette kolommen, logo in de hoek. Je vraagt om een samenvatting van de kwartaalcijfers. Het antwoord klinkt overtuigend, de zinnen lopen, het formaat klopt. Maar de cijfers kloppen niet.
Dat is het verraderlijke aan PDF's en AI. Het model geeft je geen foutmelding. Het doet zijn best met wat het krijgt, en als het iets niet goed kan lezen, vult het de gaten zelf in. Dat heet [hallucinatie](/kennisbank/ai-begrip-hallucinaties/), en het gebeurt vaker dan je denkt.
## PDF is gemaakt voor ogen, niet voor taalmodellen
Het PDF-formaat stamt uit de vroege jaren negentig. Adobe ontwikkelde het om documenten te delen die er overal identiek uitzagen: eerst op papier, later op scherm. De Amerikaanse belastingdienst was een van de eerste grote gebruikers: formulieren die er bij elke ontvanger precies hetzelfde uitzagen, zonder ze te printen en te posten. Sindsdien is PDF de standaard geworden voor iedereen die een betrouwbaar document nodig heeft: advocaten, overheden, uitgevers, pensioenfondsen.
Maar onder de motorkap is een PDF geen tekst. Het is een verzameling instructies voor het *tekenen* van tekst op een pagina: lettercoördinaten, fontkeuzes, posities in pixels.
Een taalmodel leest geen pixels. Het leest tekst. Om iets met een PDF te doen, moet het model eerst de tekst eruit halen via OCR (optical character recognition). En daar gaat het mis.

## Waar het concreet misgaat
### Tabellen
Dit is het grootste probleem. Een PDF-tabel ziet er voor ons helder uit: rijen, kolommen, getallen netjes uitgelijnd. Maar voor een taalmodel zijn het losse tekstelementen zonder structuur. Kolommen lopen door elkaar, rijen verschuiven, een getal dat bij "Q3" hoort wordt gekoppeld aan "Q2".

In een recente training lieten we een pensioendocument zien met afkoopcijfers per leeftijdsgroep. Vijf kolommen, tientallen rijen. Voor ons helder. Het taalmodel haalde de kolommen door elkaar en gaf bedragen terug die bij de verkeerde leeftijdsgroep hoorden. Niemand die dat meteen ziet als je het antwoord niet narekent.
### Kolommen en layout
Veel rapporten en academische papers gebruiken twee kolommen. OCR leest van links naar rechts en combineert tekst uit de linker- en rechterkolom tot één onleesbare brij.
Hetzelfde probleem speelt bij paginaovergangen. Een tabel die doorloopt van pagina 10 naar pagina 11 is voor ons één geheel. Voor het model zijn het twee losse fragmenten. De koptekst verdwijnt, de context breekt af.
### Visuele elementen
Een staafdiagram in een PDF is voor ons in één oogopslag duidelijk. Een taalmodel kan er weinig mee. Het ziet de assen niet, leest de labels verkeerd en mist de onderlinge verhoudingen. Organogrammen en flowcharts zijn nog lastiger: het model ziet losse tekstvakken, maar begrijpt niet hoe ze met elkaar verbonden zijn.

En dan zijn er nog de scans. Gescande documenten met slechte resolutie, scheve tekst of handgeschreven aantekeningen in de marge. Het model doet zijn best, maar de foutmarge is groot.
## Waarom dit niet snel opgelost wordt
Je zou verwachten dat dit een opgelost probleem is. Taalmodellen kunnen code schrijven, wiskundige bewijzen leveren en in meerdere talen vertalen. Maar PDF's lezen? Daar worstelen ze mee.
Het kernprobleem gaat dieper dan slechte OCR. OCR herkent tekst, maar begrijpt de *redactionele structuur* van een document niet. Een kop, een voetnoot, een bijschrift bij een grafiek: voor ons is het verschil vanzelfsprekend. Voor een model zijn het stukjes tekst op een pagina, zonder hiërarchie. Zolang het om lopende tekst gaat, werkt dat prima. Maar zodra er tabellen, formulieren of meerdere kolommen in beeld komen, valt de structuur weg.
Er wordt aan gewerkt. Een nieuwe generatie gespecialiseerde modellen pakt PDF's aan in meerdere stappen: eerst het document opdelen in regio's (koppen, tabellen, afbeeldingen, voetnoten), dan elke regio doorsturen naar een apart model dat getraind is op precies dat type element. Die aanpak is vergelijkbaar met hoe zelfrijdende auto's werken: eerst de omgeving segmenteren (auto, voetganger, wegmarkering), dan per object beslissingen nemen. Grafieken worden zo omgezet naar spreadsheets, handgeschreven aantekeningen worden ontcijferd, en tabellen houden hun kolommen.
Waarom investeren bedrijven hier nu pas serieus in? Omdat AI-ontwikkelaars ontdekten dat PDF's een enorme, onbenutte bron van hoogwaardige data zijn. Overheidsrapporten, studieboeken, wetenschappelijke papers, octrooien: het zit allemaal in PDF. Onderzoekers schatten dat er biljoenen tokens aan trainingsdata in PDF's opgesloten zitten. Dat maakt het probleem ineens commercieel interessant.
De resultaten worden beter. Maar het blijft een probabilistisch systeem: het model *gokt* wat de structuur is. In 98% van de gevallen gaat dat goed. Die laatste 2% is precies de tabel met je kwartaalcijfers, het formulier met handgeschreven aantekeningen, de scan die net iets scheef staat. En dan zijn er de randgevallen waar niemand op rekent: PDF's die andere PDF's bevatten, juridische documenten met passages die soms onderstreept en soms doorgestreept zijn, faxen van medische formulieren waar artsen overheen hebben gekrabbeld.
PDF als formaat gaat ook niet weg. De zoektrend stijgt elk jaar gestaag, zonder uitzondering. Er is simpelweg geen ander formaat dat doet wat PDF doet: een document dat er voor elke ontvanger identiek uitziet, ongeacht apparaat, browser of tijdstip. Een PDF uit 1995 opent vandaag nog precies zoals bedoeld. Overheden, advocaten, uitgevers, pensioenfondsen: ze zijn er allemaal afhankelijk van. De hoeveelheid PDF's groeit. Het probleem wordt niet kleiner.
## Wat je er zelf aan doet
De oplossing is simpeler dan je denkt. Je hoeft niet te wachten op betere modellen. Je moet je kerndocumenten omzetten.
### Gebruik het bronbestand
Heb je het originele Word-document, de Google Sheet of de Google Slides? Gebruik dat. Altijd. Het bronbestand bevat de structuur die een PDF kwijtraakt. Pas als je geen bronbestand hebt, val je terug op de PDF.
### Zet om naar platte tekst
Kopieer de inhoud van je document naar een Google Doc of een markdown-bestand. Koppen, subkoppen, opsommingen, tabellen in tekstformaat. Geen opmaak, geen logo's, geen paginanummers. Het gaat om de inhoud.
Voor Google Docs: zet de pagina-instelling op "pageless" (Bestand > Pagina-instelling). Zonder pagina's werkt het als een eindeloos notitievel, dat is precies wat een taalmodel nodig heeft.
### Laat AI het omzetten
Heb je een slide deck van 50 pagina's? Upload het naar Gemini en vraag: "Zet dit om naar gestructureerde tekst in markdown. Beschrijf ook wat je op visuele elementen ziet." Het model haalt de tekst eruit en maakt een omschrijving van grafieken en foto's. Het resultaat check je, maar het bespaart je uren handwerk.
### Tabellen apart behandelen
Tabellen zijn het kwetsbaarst. Kopieer ze uit Excel of Sheets als platte tekst, of exporteer als CSV. Een tabel in CSV-formaat leest een taalmodel foutloos. Dezelfde tabel in een PDF is onvoorspelbaar.
### Werk in het Microsoft-ecosysteem
Gebruik je Microsoft 365 met Copilot? Dan omzeil je het PDF-probleem grotendeels. Copilot leest Word-, Excel- en PowerPoint-bestanden rechtstreeks via Microsoft Graph, inclusief de oorspronkelijke structuur. Geen OCR, geen gokwerk. Dat is een van de redenen waarom werken vanuit bronbestanden zo veel betrouwbaarder is dan werken vanuit een PDF-export.
## Wanneer een PDF wél prima is
Niet alles hoeft omgezet. PDF's werken goed genoeg voor:
- Lopende tekst zonder tabellen (een beleidsdocument, een rapport in proza)
- Brainstormen en globale samenvattingen (waar exacte cijfers niet kritiek zijn)
- Documenten die je eenmalig raadpleegt (niet als onderdeel van je vaste kennisbank)
De vuistregel: als je het antwoord niet zou narekenen, is een PDF prima. Als er geld, percentages of klantnamen in staan, zet dan om.
## Het kost een middag, het bespaart je maanden
De meeste teams die we trainen hebben 10 tot 15 kerndocumenten: strategieplannen, tarieven, campagneblauwdrukken, doelgroepomschrijvingen. Die documenten zet je één keer om naar platte tekst. Daarna gebruik je ze bij alles wat je met AI doet, bijvoorbeeld als onderdeel van je [AI-kennisbank](/kennisbank/ai-kennisbank-opbouwen/).
Dat omzetten kost een middag. Het alternatief is elke keer opnieuw met je vingers kruisen dat het model de PDF deze keer wel goed leest. Dat is geen werkwijze. Dat is hopen.
## AI Begrip: Waarom medewerkers moeten snappen hoe AI werkt
> Zonder basiskennis van AI maken medewerkers vermijdbare fouten. Leer over hallucinaties, de VAK-check en wanneer je AI wel en niet kunt vertrouwen.
**Auteur:** Casimir Morreau · **Datum:** 2026-02-02
**URL:** https://copilot-academy.nl/kennisbank/ai-begrip-hallucinaties/
## De hyperintelligente stagiair
Zie een AI-assistent als een briljante stagiair met een encyclopedisch geheugen, die soms dingen verzint. Niet uit kwade wil, maar omdat hij patronen herkent en daar conclusies aan verbindt die er niet zijn.
Dat is precies hoe AI-tools als Microsoft Copilot, ChatGPT en Claude werken. Ze zijn razend snel en indrukwekkend capabel. Maar ze hebben geen begrip van wat ze schrijven. Ze "weten" niet of iets klopt.
Voor HR- en L&D-professionals is dit het vertrekpunt van elke AI-training. Want zonder dit inzicht ontstaan twee problemen: medewerkers die AI blindelings vertrouwen, of medewerkers die na één slechte ervaring afhaken. Beide kosten je organisatie geld.
Dit artikel legt uit wat je team moet begrijpen over AI, en hoe je dat begrip meetbaar maakt.
## Hoe AI antwoorden genereert
### Voorspellen, niet denken
Een taalmodel zoals GPT-4 of Copilot werkt als een geavanceerde voorspellingsmachine. Het is getraind op miljarden teksten en leert patronen herkennen. Woord voor woord genereert het een antwoord door steeds het meest waarschijnlijke volgende woord te kiezen.
Vraag je: *"De hoofdstad van Frankrijk is..."* Dan voorspelt het model "Parijs" met 99% zekerheid. Niet omdat het weet dat Parijs de hoofdstad is, maar omdat in de trainingsdata "Frankrijk" en "Parijs" vrijwel altijd samen voorkomen.
### Geen begrip, geen geheugen
Dit heeft drie consequenties die je team moet kennen:
1. **AI begrijpt niet wat het schrijft.** Het herkent patronen, maar heeft geen concept van waarheid of betekenis.
2. **Elk antwoord is nieuw gegenereerd.** Zelfs dezelfde vraag kan een ander antwoord opleveren, want AI is non-deterministisch.
3. **AI kent je organisatie niet.** Het is getraind op algemene tekst van het internet, niet op jouw interne processen, klanten of bedrijfscultuur. Dat kun je oplossen met [contextbeheer](/kennisbank/context-management-ai-werkomgeving/).
Voor medewerkers betekent dit: AI is een hulpmiddel, geen betrouwbare informatiebron. Dat onderscheid moet iedereen in je team snappen.
## Hallucinaties: het grootste risico
AI-hallucinaties zijn antwoorden die overtuigend klinken maar feitelijk onjuist zijn. De beste modellen hallucineren in circa 2% van de antwoorden. Dat klinkt weinig, tot je beseft dat je team dagelijks tientallen AI-interacties heeft.
### De 4 types hallucinaties
**1. Feitelijke onjuistheden**
AI presenteert statistieken, datums of gebeurtenissen die niet kloppen. Een medewerker vraagt om marktcijfers en krijgt overtuigende percentages die nergens op gebaseerd zijn.
> *Voorbeeld: "De Nederlandse AI-markt groeide in 2025 met 34,7%." Dit klinkt precies genoeg om te geloven, maar het cijfer is verzonnen.*
**2. Verzonnen details**
Namen, producten of technische specificaties die niet bestaan maar aannemelijk klinken.
> *Voorbeeld: een medewerker vraagt Copilot om een referentie en krijgt "volgens het onderzoek van Van der Berg & Willemsen (2024, Universiteit Utrecht)". De onderzoekers en publicatie bestaan niet.*
**3. Logische fouten**
Rekenfouten of tegenstrijdige redeneringen die de conclusie onbetrouwbaar maken.
> *Voorbeeld: een financieel overzicht waar de deelbedragen niet optellen tot het totaal, maar de conclusie "binnen budget" luidt.*
**4. Fictieve bronnen**
Niet-bestaande onderzoeken, artikelen of experts die als referentie worden opgevoerd.
> *Voorbeeld: "Bron: McKinsey Digital Workplace Report 2025, pagina 47". Het rapport bestaat niet in die vorm.*
### Waarom hallucinaties gevaarlijk zijn in organisaties
In een kantooromgeving worden AI-gegenereerde teksten vaak direct doorgestuurd, in presentaties verwerkt of als basis voor beslissingen gebruikt. Als niemand controleert, verspreiden hallucinaties zich als feiten door de organisatie.
In onze trainingen zien we dat het merendeel van de deelnemers bij de nulmeting AI-output doorstuurt zonder controle.
## De VAK-check: drie vragen voor elke AI-output
Om hallucinaties te vangen voordat ze schade aanrichten, trainen wij medewerkers in de **VAK-check**. Drie vragen die je stelt voordat je AI-output gebruikt:
### V: Verifieerbaar
*Kan ik deze informatie controleren via een betrouwbare bron?*
Controleer feiten, cijfers en namen. Als AI een statistiek noemt, zoek de originele bron. Als AI een naam noemt, check of die persoon bestaat en of de context klopt.
**Vuistregel:** hoe specifieker het detail (een exact percentage, een datum, een naam), hoe groter de kans op een hallucinatie.
### A: Accuraat
*Kloppen de berekeningen en is de redenering logisch?*
Check of getallen optellen, of conclusies volgen uit de premissen, en of er geen tegenstrijdigheden in het antwoord zitten. AI is verrassend slecht in rekenen en logisch redeneren.
### K: Kloppend
*Komt dit overeen met wat ik als professional weet?*
Dit is de belangrijkste check. Jij bent de vakexpert, niet de AI. Als iets "niet lekker voelt" of afwijkt van wat je uit ervaring weet, vertrouw dan je eigen expertise.
**De VAK-check in de praktijk:**
| Situatie | V | A | K | Actie |
|----------|---|---|---|-------|
| Copilot vat een vergadering samen | ✓ Check namen aanwezigen | ✓ Check genoemde deadlines | ✓ Was ik erbij? Klopt dit? | Controleer en verstuur |
| AI schrijft een klantenmail | Geen feiten om te checken | ✓ Klopt de toon? | ✓ Past dit bij de relatie? | Review toon en inhoud |
| AI genereert marktcijfers | ✗ Bron opzoeken! | ✓ Tellen de delen op? | ✓ Realistisch? | Verifieer of vervang |
## Wanneer kun je AI vertrouwen? Het stoplichtmodel
Niet elke AI-taak vereist dezelfde mate van controle. Het stoplichtmodel helpt medewerkers inschatten hoeveel verificatie nodig is:
### Groen: laag risico
Taken waarbij fouten weinig impact hebben en makkelijk te corrigeren zijn.
- Brainstormen en ideeën genereren
- Eerste concepten schrijven die je zelf bewerkt
- Tekst samenvatten die je al kent
- Interne communicatie zonder feitelijke claims
**Controleniveau:** snel scannen, toon en stijl checken.
### Geel: gemiddeld risico
Taken waarbij fouten merkbaar zijn maar geen grote schade veroorzaken.
- E-mails naar klanten of partners
- Presentaties voor intern gebruik
- Vergadernotities en actiepunten
- Documenten die door anderen worden gelezen
**Controleniveau:** VAK-check toepassen, namen en feiten verifiëren.
### Rood: hoog risico
Taken waarbij fouten serieuze consequenties hebben.
- Juridische documenten of adviezen
- Financiële rapporten met cijfers
- Externe publicaties namens de organisatie
- Beslissingen op basis van AI-gegenereerde data
- Alles met privacy-gevoelige informatie
**Controleniveau:** volledige verificatie, laten reviewen door tweede persoon, bronnen checken.
**Voor managers:** als je team het stoplichtmodel consequent toepast, voorkom je de twee meest voorkomende AI-incidenten: het doorsturen van foutieve informatie en het delen van vertrouwelijke data met AI-tools.
## EU AI Act: wat je organisatie moet weten
Sinds 2025 stelt de EU AI Act eisen aan hoe organisaties AI inzetten. Voor de meeste kantooromgevingen is de directe impact beperkt: tools als Copilot vallen in de categorie "beperkt risico". Maar er zijn verplichtingen waar je organisatie rekening mee moet houden:
- Medewerkers en klanten moeten weten wanneer ze met AI-gegenereerde content te maken hebben (transparantie)
- Bij belangrijke beslissingen mag AI adviseren, maar een mens neemt de eindbeslissing (menselijk toezicht)
- De AI Act versterkt bestaande AVG-verplichtingen rond het gebruik van persoonsgegevens (data en privacy)
AI-begrip bij medewerkers is een eerste stap richting compliance. Wie begrijpt wat AI wel en niet kan, maakt betere keuzes over wanneer en hoe het wordt ingezet.
De meeste organisaties die we spreken hebben nog geen formeel AI-beleid. Dat verandert snel nu de EU AI Act in werking is getreden.
## Observeerbaar gedrag per niveau
Als HR- of L&D-professional wil je niet alleen weten *of* medewerkers AI begrijpen, maar ook *hoe goed*. Onderstaande tabel beschrijft concreet observeerbaar gedrag per niveau:
| | Starter | Basis | Vaardig |
|---|---------|-------|---------|
| **Vertrouwen & verificatie** | Weet dat AI fouten maakt, controleert incidenteel | Past de VAK-check toe op belangrijke output | Voorspelt waar AI moeite zal hebben, ontwerpt verificatieprocessen voor het team |
| **Taakselectie** | Gebruikt AI voor eenvoudige, laag-risico taken | Schat bewust in welke taken geschikt zijn (stoplichtmodel) | Bepaalt AI-strategie per projecttype, adviseert collega's |
| **Uitleg & overdracht** | Kan vertellen dat AI "soms fouten maakt" | Kan aan collega's uitleggen *waarom* AI soms foute informatie geeft | Geeft trainingen of workshops over AI-begrip aan teamleden |
| **Risicobewustzijn** | Deelt geen gevoelige data met publieke AI-tools | Kent het verschil tussen bedrijfs-AI en publieke tools, volgt richtlijnen | Draagt bij aan het AI-beleid van de organisatie |
**Hoe je dit meet:**
- Starter: intake-assessment of eerste zelfscan
- Basis: na de [AI Skills Basistraining](/training/microsoft-copilot-basis-training/) (portfolio-opdracht: VAK-check op eigen werkvoorbeeld)
- Vaardig: na de [AI Werkproces Training](/training/ai-werkproces/) en certificering
## Volgende stap: van begrip naar actie
AI begrijpen is de fundering. Maar begrip alleen levert nog geen betere output op. De volgende stap is leren om AI effectief aan te sturen, met gestructureerde instructies die consistent bruikbare resultaten opleveren.
Lees verder: **[Effectief Prompten: Van vage opdracht naar bruikbaar resultaat](/kennisbank/effectief-prompten-voor-teams/)**
Of ga terug naar het overzicht: **[De 3 AI-vaardigheden die je organisatie nodig heeft](/kennisbank/drie-essentiele-ai-skills/)**
## Contextbeheer: Hoe je AI leert je organisatie te begrijpen
> AI weet niets over je organisatie. Met contextdocumenten en een gestructureerde AI-werkomgeving krijg je output die direct bruikbaar is.
**Auteur:** Casimir Morreau · **Datum:** 2026-02-02
**URL:** https://copilot-academy.nl/kennisbank/context-management-ai-werkomgeving/
## Het contextprobleem
Je medewerker opent Copilot en typt: "Schrijf een voorstel voor thuiswerken." Het resultaat? Een generiek Amerikaans document over remote work, met verwijzingen naar wetgeving die niet bestaat in Nederland. Onbruikbaar.
Dit is het contextprobleem. AI-tools zijn getraind op miljarden teksten van het internet, maar ze weten niets over jouw organisatie. Ze kennen je klanten niet, je interne processen niet, je huisstijl niet, je CAO niet. Elke keer dat een medewerker een nieuwe chat opent, begint AI met een blanco lei.
Het verschil tussen een nieuwe medewerker en een ervaren collega? De ervaren collega kent de context. Diezelfde sprong kun je maken met AI, als je het de juiste informatie geeft.
Dit is de derde en misschien wel de meest onderschatte AI-vaardigheid: **contextbeheer**. Het vermogen om AI systematisch te voorzien van de informatie die het nodig heeft om output te leveren die past bij jouw specifieke situatie.
## Wat is een contextdocument?
Een contextdocument is een bestand dat achtergrondinformatie bevat die je aan AI meegeeft. Het is geen prompt, het is de *kennis* die achter de prompt zit.
Vergelijk het met het verschil tussen een briefing en een opdracht. De opdracht is: "Schrijf een klantenmail." De briefing is alles wat de schrijver moet weten om die mail goed te schrijven: wie is de klant, wat is de relatie, welke toon gebruiken we, wat is er eerder besproken.
### Types contextdocumenten
**Organisatiecontext**: bedrijfsprofiel (sector, omvang), huisstijl en tone of voice, interne termen en jargon.
**Teamcontext**: teamsamenstelling en rollen, lopende projecten, werkprocessen en procedures.
**Persoonlijke context**: je rol en verantwoordelijkheden, terugkerende taken, voorkeursstijl in communicatie.
**Taakspecifieke context**: klantprofielen, productinformatie, beleidsdocumenten, vergadernotities en projectdocumentatie.
## De AI-werkomgeving: drie mappen
In onze trainingen leren we medewerkers een gestructureerde AI-werkomgeving opzetten. Het principe is simpel: drie mappen die je AI-werk organiseren.
```
AI-werkomgeving/
├── Promptbibliotheek/ → Geteste, herbruikbare prompts per taaktype
├── Contextdocumenten/ → Organisatie-, team- en persoonlijke context
└── Projecten/ → Lopend werk, bronnen en AI-output
```
### Promptbibliotheek
Hier bewaar je prompts die je hebt getest en verfijnd. Niet als losse experimenten, maar als herbruikbare templates voor terugkerend werk. Een medewerker die wekelijks vergadernotities maakt, heeft één geteste prompt die elke keer werkt, in plaats van elke week opnieuw te improviseren.
### Contextdocumenten
Dit is het hart van contextbeheer. Je maakt een beperkt aantal documenten (vaak 3-5) die je herhaaldelijk meestuurt of koppelt aan je AI-tool. Eén keer goed opzetten bespaart wekelijks tijd.
### Projecten
Hier sla je lopend werk op: bronnen die je aan AI voert, tussenresultaten, en definitieve output. Zo voorkom je dat je steeds dezelfde informatie opnieuw moet invoeren.
**Het resultaat:** medewerkers die met een AI-werkomgeving werken, besteden minder tijd aan het herhalen van instructies en meer tijd aan het verfijnen van output.
Medewerkers met een ingerichte AI-werkomgeving besparen structureel tijd doordat ze instructies niet hoeven te herhalen.
## Van generieke naar organisatie-output
Het verschil dat context maakt, is dramatisch. Hieronder een voorbeeld uit de praktijk:
### Zonder context
**Prompt:** "Schrijf een voorstel voor hybride werken bij onze zorginstelling."
**Resultaat:**
- Generiek Amerikaans document over "remote work"
- Standaard kantoortermen, niet relevant voor zorg
- Verwijzing naar verouderde of niet-bestaande wetgeving
- Geen rekening met 24/7 diensten of patiëntveiligheid
### Met context
**Prompt:** "Schrijf een voorstel voor hybride werken voor onze zorginstelling."
**Contextdocument meegestuurd:**
- Organisatie: regionale zorginstelling, 1.200 medewerkers, 3 locaties
- CAO: CAO-Zorg met specifieke bepalingen over werktijden
- Situatie: 24/7 diensten, patiëntveiligheid heeft prioriteit
- Doelgroep: OR en directie
- Perspectief: HR-adviseur
**Resultaat:**
- Specifiek voor de Nederlandse zorgsector
- Correcte verwijzing naar CAO-Zorg voorwaarden
- Borging van continuïteit van zorg als uitgangspunt
- Praktisch implementatieplan per locatie
- Geschreven in taal die past bij OR en directie
Hetzelfde model, dezelfde vraag, maar een fundamenteel ander resultaat. Het verschil is uitsluitend de context.
## Herbruikbare templates: de prompt + context formule
De kracht van contextbeheer zit in herbruikbaarheid. In plaats van elke keer opnieuw alle informatie in te typen, combineer je een vaste prompt met een contextdocument.
### De formule
```
Startprompt (TAAK + ROL + FORMAT) + Contextdocument = Organisatie-specifieke output
```
### Voorbeeld: wekelijkse klantupdate
**Startprompt (bewaard in promptbibliotheek):**
> TAAK: Schrijf een beknopte klantupdate voor de accountmanager.
> ROL: Je bent een ervaren communicatieadviseur in de zakelijke dienstverlening.
> FORMAT: Max 200 woorden. Structuur: voortgang (3 bullets), aandachtspunten (2 bullets), volgende stap (1 zin).
**Contextdocument (bewaard in contextdocumenten):**
> Klant: [Bedrijfsnaam], sector: financieel, contactpersoon: [Naam] (afdelingshoofd operations).
> Relatie: bestaande klant sinds 2023. Toon: professioneel maar persoonlijk, gebruik voornaam.
> Lopend project: [Projectnaam], fase: implementatie, deadline: Q2 2026.
> Aandachtspunt: klant hecht aan transparantie over risico's.
**Input (wisselend per week):**
> Afgelopen week: [plak hier de relevante notities of actiepunten]
De startprompt en het contextdocument blijven gelijk. Alleen de input verandert. Resultaat: consistente, kwalitatieve output in een fractie van de tijd.
Wil je dieper in de promptstructuur duiken? Lees meer over de vier bouwstenen in ons artikel over [effectief prompten](/kennisbank/effectief-prompten-voor-teams/).
## Waarom contextbeheer AI-adoptie schaalbaar maakt
De eerste twee AI-vaardigheden ([AI begrijpen](/kennisbank/ai-begrip-hallucinaties/) en [effectief prompten](/kennisbank/effectief-prompten-voor-teams/)) zijn individuele skills. Contextbeheer is de vaardigheid die AI-gebruik schaalbaar maakt binnen een organisatie.
### Van individueel naar team
Wanneer één medewerker een goed contextdocument maakt, kan het hele team daarvan profiteren. Een huisstijldocument dat iedereen meestuurt. Een klantprofiel dat het hele accountteam gebruikt. Procesbeschrijvingen die nieuwe medewerkers direct aan AI kunnen voeden. Lees hoe je dit opschaalt naar een volledige [AI-kennisbank](/kennisbank/ai-kennisbank-opbouwen/).
### Van incidenteel naar structureel
Zonder AI-werkomgeving is elk AI-gebruik een losstaand experiment. Met een werkomgeving wordt AI een structureel onderdeel van het werkproces. Medewerkers hoeven niet elke keer opnieuw het wiel uit te vinden.
### Het ROI-argument
De grootste tijdsbesparing zit niet in het genereren van antwoorden (dat doet AI in seconden). De tijdsbesparing zit in het *niet hoeven herschrijven* van onbruikbare output. Medewerkers met goede context besteden minder tijd aan het corrigeren van generieke resultaten en meer tijd aan werk dat er toe doet.
Organisaties met een gestructureerde AI-aanpak melden consistent minder tijd kwijt te zijn aan het herschrijven van onbruikbare output.
Organisaties die contextbeheer serieus nemen, zien een verschuiving: van "AI werkt niet voor ons" naar "AI begrijpt hoe wij werken."
## Observeerbaar gedrag per niveau
Hoe herken je of medewerkers contextbeheer beheersen? Onderstaande tabel beschrijft concreet gedrag per niveau:
| | Starter | Basis | Vaardig |
|---|---------|-------|---------|
| **Contextgebruik** | Geeft minimale of geen context mee aan AI | Stuurt relevante contextdocumenten mee bij complexe taken | Beheert project-brede context, houdt documenten actueel |
| **AI-werkomgeving** | Slaat output sporadisch op, geen vaste structuur | Heeft een werkende mappenstructuur (3 mappen) op eigen systeem | Onderhoudt gedeelde AI-werkomgeving voor het team |
| **Herbruikbaarheid** | Begint elke AI-interactie vanaf nul | Heeft minimaal 1 herbruikbaar contextdocument, combineert dit met vaste prompts | Bouwt en onderhoudt templates die collega's kunnen gebruiken |
| **Efficiëntie** | Besteedt veel tijd aan het corrigeren van generieke output | Krijgt in eerste instantie bruikbare output door goede context | Ervaart merkbare tijdsbesparing, kan dit kwantificeren |
**Hoe je dit meet:**
- Starter: intake-assessment, medewerker beschrijft hoe hij/zij nu AI gebruikt
- Basis: na de [AI Skills Basistraining](/training/microsoft-copilot-basis-training/) (portfolio-opdracht: werkende AI-werkomgeving met minimaal 1 contextdocument)
- Vaardig: na de [AI Werkproces Training](/training/ai-werkproces/) en certificering
## Volgende stap: het complete framework
Je hebt nu de drie AI-vaardigheden verkend: [AI begrijpen](/kennisbank/ai-begrip-hallucinaties/), [effectief prompten](/kennisbank/effectief-prompten-voor-teams/), en contextbeheer. Samen vormen ze het framework waarmee je medewerkers structureel leert werken met AI.
Ga terug naar het overzicht voor het complete plaatje: **[De 3 AI-vaardigheden die je organisatie nodig heeft](/kennisbank/drie-essentiele-ai-skills/)**
## Effectief Prompten: Van vage opdracht naar bruikbaar resultaat
> Waarom 'slechte prompts' geen luiheid zijn maar een communicatieprobleem. Leer de bouwstenen, iteratietechnieken en observeerbaar gedrag per niveau.
**Auteur:** Robert Vos · **Datum:** 2026-02-02
**URL:** https://copilot-academy.nl/kennisbank/effectief-prompten-voor-teams/
## Waarom "slechte prompts" geen luiheid zijn
Een medewerker typt in Copilot: "Maak een samenvatting van dit rapport." Het resultaat is generiek, te lang en mist de kern. De medewerker concludeert: "AI werkt niet." Herkenbaar?
Het probleem is geen luiheid en geen gebrek aan talent. Het probleem is dat prompten een **communicatievaardigheid** is die niemand heeft geleerd. We verwachten van medewerkers dat ze effectief communiceren met een tool die ze niet begrijpen, in een formaat dat ze nooit eerder hebben gebruikt.
Geef een nieuwe collega de opdracht "Maak een samenvatting" en je krijgt terug: van welk rapport? Voor wie? Hoe lang? Welke onderdelen zijn belangrijk? AI stelt die vragen niet. Het raadt en levert generieke output.
De oplossing is geen promptverzameling die medewerkers kopiëren en plakken. De oplossing is medewerkers leren *hoe* ze communiceren met AI. Dat is een vaardigheid die je kunt trainen en verbeteren.
## De 4 bouwstenen van een effectieve prompt
In onze trainingen gebruiken we het **TAAK/CONTEXT/ROL/FORMAT framework** (TCRF). Vier bouwstenen die samen een heldere instructie vormen:
### 1. TAAK: Wat moet AI doen?
Begin met een werkwoord. Wees specifiek over het eindresultaat.
- **Vaag:** "Schrijf iets over het project"
- **Specifiek:** "Schrijf een voortgangsrapportage van maximaal 300 woorden voor het MT over Project Atlas"
### 2. CONTEXT: Welke achtergrond is relevant?
AI weet niets over jouw situatie. Geef de informatie mee die een collega ook nodig zou hebben.
- **Zonder context:** "Schrijf een e-mail aan een klant"
- **Met context:** "Schrijf een e-mail aan Marieke de Vries (HR-manager bij BNG Bank). Vorige week deden we een pilot met 15 deelnemers, score 4.8/5. Doel: follow-up plannen."
### 3. ROL: Welk perspectief moet AI aannemen?
Door een rol te geven, stuur je de toon, het detailniveau en de expertise van de output.
- **Zonder rol:** "Geef feedback op dit rapport"
- **Met rol:** "Je bent een senior redacteur met ervaring in zakelijke communicatie. Geef feedback op helderheid, structuur en overtuigingskracht."
### 4. FORMAT: Hoe moet het resultaat eruitzien?
Geef aan welke vorm je verwacht. Dit voorkomt dat je na het genereren alsnog moet herformatteren.
- **Zonder format:** "Geef tips voor de vergadering"
- **Met format:** "Geef 5 tips als genummerde lijst. Per tip: titel in 3-5 woorden, gevolgd door uitleg in 1 zin."
De uitgebreide uitleg per bouwsteen met meer voorbeelden vind je in onze [AI Skills Basistraining](/training/microsoft-copilot-basis-training/).
## Twee voorbeelden uit de HR/L&D-praktijk
### Voorbeeld 1: Trainingsvoorstel schrijven
**Zwakke prompt:**
> Schrijf een voorstel voor een AI-training.
**Resultaat:** een generiek document dat niet past bij de organisatie, zonder budget, zonder doelgroep, zonder meetbare doelen.
**Sterke prompt:**
> **TAAK:** Schrijf een voorstel van 1 A4 voor een AI-vaardigheidstraining voor onze afdeling HR (12 medewerkers).
>
> **CONTEXT:** We gebruiken Microsoft 365 met Copilot-licenties sinds 3 maanden. Adoptie is laag: 4 van de 12 gebruiken Copilot actief. Management wil dat het hele team binnen Q2 op basisniveau zit. Budget: €5.000.
>
> **ROL:** Je bent een L&D-adviseur met ervaring in digitale transformatie bij middelgrote organisaties.
>
> **FORMAT:** Structuur: aanleiding (3 zinnen), doelstelling (SMART), aanpak (3 stappen), investering, verwacht resultaat. Toon: zakelijk, overtuigend voor MT.
**Resultaat:** een gericht voorstel dat direct naar het MT kan, met concrete cijfers en een implementatieplan.
### Voorbeeld 2: Evaluatieformulier ontwerpen
**Zwakke prompt:**
> Maak een evaluatieformulier voor een training.
**Resultaat:** een standaard smiley-formulier met vragen als "Hoe tevreden bent u?". Weinig bruikbaar voor verbetering.
**Sterke prompt:**
> **TAAK:** Ontwerp een evaluatieformulier dat zowel tevredenheid als leereffect meet na een AI-vaardigheidstraining.
>
> **CONTEXT:** Deelnemers zijn kenniswerkers (HBO+), training duurt 1 dag, focus op prompten en AI-werkomgeving inrichten. We willen meten of deelnemers de vaardigheden in de praktijk toepassen.
>
> **ROL:** Je bent een learning consultant gespecialiseerd in Kirkpatrick's evaluatiemodel.
>
> **FORMAT:** 10 vragen: 4 over reactie (5-puntsschaal), 3 over leren (open + gesloten), 3 over gedragsintentie. Eindig met 1 open vraag. Formuleer in "je"-vorm.
**Resultaat:** een professioneel formulier dat onderscheid maakt tussen tevredenheid en daadwerkelijk leereffect.
## Het gesprek na de eerste prompt
Een veelgemaakte fout: na het eerste resultaat opgeven of het zonder aanpassing overnemen. Effectief prompten is iteratief. Je werkt in een gesprek met AI.
### Hoe iteratie werkt
1. **Stuur je startprompt** (met de 4 bouwstenen)
2. **Beoordeel het resultaat**: wat is goed, wat mist?
3. **Geef gerichte feedback**: niet "maak het beter" maar specifiek wat je wilt veranderen
4. **Herhaal** tot het resultaat bruikbaar is
### Feedback die werkt
| In plaats van... | Zeg... |
|-----------------|--------|
| "Dit is niet goed" | "De toon is te formeel voor deze doelgroep. Maak het persoonlijker, gebruik 'je' in plaats van 'u'." |
| "Maak het beter" | "Voeg concrete voorbeelden toe bij punt 2 en 4. Maak de conclusie 50% korter." |
| "Nog een keer" | "Herschrijf de inleiding vanuit het perspectief van de manager, niet de medewerker." |
### Wanneer opnieuw beginnen?
Soms is itereren niet genoeg. Begin een nieuw gesprek wanneer:
- De richting fundamenteel verkeerd is (AI heeft de opdracht anders geïnterpreteerd)
- Je halverwege van aanpak wilt veranderen
- Het gesprek te lang wordt en AI [context verliest](/kennisbank/context-management-ai-werkomgeving/)
**Vuistregel:** 2-3 iteraties is normaal. Na 5 iteraties zonder verbetering: herformuleer je startprompt of begin opnieuw.
## Complexe taken opdelen
AI presteert beter op gerichte taken dan op brede opdrachten. Een megatprompt van 500 woorden die 10 dingen tegelijk vraagt, levert bijna altijd matig resultaat.
### De 3-stappenmethode
**Stap 1: Laat AI de structuur bepalen**
> "Ik wil een onboardingprogramma voor nieuwe medewerkers schrijven. Welke onderdelen moet dit programma bevatten? Geef een inhoudsopgave."
**Stap 2: Werk per onderdeel uit**
> "Werk onderdeel 3 'Eerste werkweek' uit. Context: [specifieke informatie]. Format: dagprogramma met activiteiten en verantwoordelijke personen."
**Stap 3: Combineer en verfijn**
> "Hier zijn de uitgewerkte onderdelen [plak ze samen]. Maak de overgangen vloeiend, verwijder overlap en zorg dat de toon consistent is."
Je krijgt beter resultaat én meer controle over het eindproduct.
## Wat managers moeten zien
Als manager of L&D-professional hoef je niet elke prompt te lezen. Maar je kunt wel herkennen of medewerkers de vaardigheid ontwikkelen:
**Signalen van groei:**
- Medewerker besteedt iets meer tijd aan de prompt, maar krijgt sneller bruikbaar resultaat
- Output hoeft minder handmatig te worden aangepast
- Medewerker kan uitleggen *waarom* een prompt goed of slecht werkte
- Medewerker deelt werkende prompts met collega's
**Signalen van stagnatie:**
- Medewerker typt steeds korte, vage opdrachten
- Output wordt standaard volledig herschreven
- Medewerker zegt "AI werkt niet voor mijn werk"
- Geen opgeslagen prompts, elke keer opnieuw beginnen
## Observeerbaar gedrag per niveau
| | Starter | Basis | Vaardig |
|---|---------|-------|---------|
| **Promptkwaliteit** | Schrijft eenvoudige, korte instructies | Gebruikt alle 4 bouwstenen (TCRF) in startprompts | Maakt herbruikbare prompttemplates voor terugkerende taken |
| **Iteratie** | Accepteert eerste output of geeft op | Verfijnt output met minimaal 2 gerichte follow-ups | Lost outputproblemen methodisch op, weet wanneer opnieuw te beginnen |
| **Werkwijze** | Typt prompts direct in de chatinterface | Schrijft startprompts extern (in document) voordat ze worden ingevoerd | Beheert een promptbibliotheek, optimaliseert prompts voor specifieke use cases |
| **Kennisdeling** | Gebruikt AI individueel, deelt geen aanpak | Slaat werkende prompts op voor eigen hergebruik | Deelt prompts en best practices met het team |
**Hoe je dit meet:**
- Starter: intake-assessment of eerste observatie
- Basis: na de [AI Skills Basistraining](/training/microsoft-copilot-basis-training/) (portfolio-opdracht: ontwikkelde startprompt met alle 4 bouwstenen, getest en verfijnd)
- Vaardig: na de [AI Werkproces Training voor je kenniswerk](/training/ai-werkproces/) en certificering
## De valkuil van promptverzamelingen
Een laatste waarschuwing. Het is verleidelijk om medewerkers een lijst met "de beste prompts" te geven en te denken dat het probleem is opgelost. Dat werkt niet.
Promptverzamelingen zijn nuttig als referentie, maar ze vervangen de vaardigheid niet. Een gekopieerde prompt werkt zolang de situatie precies overeenkomt. Zodra de context verandert (andere klant, ander document, andere toon), moet de medewerker de prompt kunnen *aanpassen*. Dat vereist begrip van de bouwstenen, niet het kopiëren van voorbeelden.
Je kunt iemand een recept geven, en dat recept zal werken. Maar een kok die de principes begrijpt (waarom je iets bakt, wat smaakbalans is) kan improviseren wanneer een ingredient ontbreekt. Dat is het verschil tussen een promptverzameling en promptvaardigheid.
Investeer daarom in de vaardigheid, niet alleen in de verzameling.
## Volgende stap: van prompt naar context
Je weet nu hoe je effectieve instructies geeft aan AI. Maar de kwaliteit van je output wordt niet alleen bepaald door je prompt. Het wordt bepaald door de *informatie* die AI tot zijn beschikking heeft.
Lees verder: [Contextbeheer: Hoe je AI leert je organisatie te begrijpen](/kennisbank/context-management-ai-werkomgeving/)
Of ga terug naar het overzicht: [De 3 AI-vaardigheden die je organisatie nodig heeft](/kennisbank/drie-essentiele-ai-skills/)
## De 3 AI-vaardigheden die je organisatie nodig heeft
> Waarom AI-licenties zonder vaardigheden niet werken. Ontdek de drie skills (AI begrip, effectief prompten en contextbeheer) en hoe je ze meetbaar maakt.
**Auteur:** Robert Vos · **Datum:** 2026-01-10
**URL:** https://copilot-academy.nl/kennisbank/drie-essentiele-ai-skills/
## Waarom "gewoon uitproberen" niet werkt
Je organisatie heeft geïnvesteerd in AI-licenties. Microsoft 365 Copilot is uitgerold, de technologie staat klaar. Maar na drie maanden blijkt: een deel van het team gebruikt het dagelijks, een groter deel heeft het na twee weken laten liggen.
Dit patroon zien we bij vrijwel elke organisatie die we begeleiden. Het probleem is niet de technologie. Het probleem is de aanname dat medewerkers vanzelf leren werken met AI.
Bij organisaties zonder gestructureerde training zien we dat het merendeel van de medewerkers na drie maanden stopt met AI of het alleen voor basistaken gebruikt.
### De teleurstellingscyclus
Het verloopt bijna altijd hetzelfde:
1. Licenties worden uitgedeeld, medewerkers proberen het uit
2. De output is generiek, niet bruikbaar, soms ronduit fout
3. "AI werkt niet voor mijn werk", de licentie blijft ongebruikt
4. Management ziet geen rendement op de investering
De oplossing is niet meer licenties, betere tools of strengere adoptie-KPI's. De oplossing is **vaardigheden**. Medewerkers die weten hoe ze met AI moeten werken, halen er consistent waarde uit. Medewerkers die het niet weten, haken af.
## Drie vaardigheden, niet drie tools
Bij Copilot Academy trainen we medewerkers in drie kernvaardigheden. Niet drie tools, niet drie features, maar drie vaardigheden die werken met elke AI-tool, of dat nu Copilot, ChatGPT of Claude is.
De metafoor die we gebruiken: zie AI als een **hyperintelligente stagiair**. Enorm capabel, snel, en met toegang tot een encyclopedische hoeveelheid kennis. Maar: geen ervaring met jouw organisatie, geen besef van wat belangrijk is, en af en toe een antwoord dat er goed uitziet maar niet klopt.
Om effectief samen te werken met deze stagiair heb je drie dingen nodig:
1. **Begrijpen wat de stagiair kan en niet kan** → AI Begrip
2. **Heldere opdrachten geven** → Effectief Prompten
3. **De stagiair de juiste achtergrondinformatie geven** → Contextbeheer
Deze drie vaardigheden bouwen op elkaar. Je kunt niet goed prompten zonder AI te begrijpen. En je prompts worden pas echt krachtig als je context toevoegt. Daarom behandelen we ze in deze volgorde.
## Skill 1: AI Begrip
De eerste vaardigheid is begrijpen hoe AI werkt. Niet technisch, maar functioneel. Medewerkers die dit begrijpen, weten wanneer ze AI kunnen vertrouwen en wanneer ze extra moeten controleren.
Dit omvat:
- Hoe taalmodellen antwoorden genereren (voorspelling, geen begrip)
- Waarom AI hallucineert en hoe je dat herkent
- De VAK-check: drie vragen voor elke AI-output
- Het stoplichtmodel: wanneer snel scannen, wanneer grondig verifiëren
Zonder AI-begrip ontstaan twee risico's: medewerkers die alles blind overnemen, of medewerkers die na één fout AI compleet afwijzen. Beide zijn kostbaar.
**Lees het volledige artikel:** [AI Begrip: Waarom medewerkers moeten snappen hoe AI werkt](/kennisbank/ai-begrip-hallucinaties/)
## Skill 2: Effectief Prompten
De tweede vaardigheid is het geven van gestructureerde instructies. Het verschil tussen een vage opdracht en een bruikbaar resultaat zit vrijwel altijd in de kwaliteit van de prompt.
Dit omvat:
- De 4 bouwstenen: Taak, Context, Rol, Format (het TCRF-framework)
- Iteratief werken: het gesprek ná de eerste prompt
- Complexe taken opdelen in gerichte stappen
- De valkuil van promptverzamelingen (begrip > kopiëren)
Prompten is geen technische skill, het is een communicatievaardigheid. En net als elke communicatievaardigheid kun je het leren, oefenen en verbeteren.
**Lees het volledige artikel:** [Effectief Prompten: Van vage opdracht naar bruikbaar resultaat](/kennisbank/effectief-prompten-voor-teams/)
## Skill 3: Contextbeheer
De derde vaardigheid, en de meest onderschatte, is contextbeheer. AI weet niets over je organisatie, je klanten, je processen. Elke chat begint met een blanco lei.
Dit omvat:
- Wat contextdocumenten zijn en hoe je ze maakt
- De AI-werkomgeving: drie mappen die je AI-werk structureren
- Van generieke naar organisatie-specifieke output
- Herbruikbare templates: prompt + context = consistent resultaat
Contextbeheer is de vaardigheid die AI-gebruik schaalbaar maakt. Eén goed contextdocument kan door het hele team worden gebruikt. Dat is het verschil tussen individueel experimenteren en organisatiebrede adoptie.
**Lees het volledige artikel:** [Contextbeheer: Hoe je AI leert je organisatie te begrijpen](/kennisbank/context-management-ai-werkomgeving/)
## Hoe je AI-vaardigheden meet
Als HR- of L&D-professional wil je niet alleen weten *of* medewerkers met AI werken, maar ook *hoe goed*. Wij werken met drie niveaus die aansluiten bij observeerbaar gedrag op de werkvloer:
### Overzicht per niveau
| Vaardigheid | Starter | Basis | Vaardig |
|-------------|---------|-------|---------|
| **AI Begrip** | Weet dat AI fouten maakt, controleert incidenteel | Past VAK-check toe, schat taken bewust in | Voorspelt AI-beperkingen, ontwerpt verificatieprocessen |
| **Effectief Prompten** | Schrijft korte, vage instructies | Gebruikt alle 4 TCRF-bouwstenen, itereert | Maakt herbruikbare templates, deelt met team |
| **Contextbeheer** | Geeft minimale context, geen structuur | Heeft AI-werkomgeving met contextdocumenten | Beheert teamcontext, ervaart meetbare tijdsbesparing |
### Wat elk niveau betekent
**Starter**: experimenteert ad-hoc met AI
> "Ik kan AI inzetten voor eenvoudige taken zoals samenvatten en concepten schrijven, waarbij ik de output controleer."
**Basis**: past AI gestructureerd toe op eigen werk
> "Ik schrijf gestructureerde prompts, controleer output systematisch en werk met een georganiseerde AI-omgeving."
**Vaardig**: ontwerpt herbruikbare AI-werkprocessen
> "Ik ontwerp AI-workflows voor mezelf en mijn team. Ik weet waar AI wel en niet werkt, en kan mijn aanpak overdragen."
### Hoe je meet
Per vaardigheid beschrijven we **observeerbaar gedrag**: concreet en toetsbaar. Geen abstracte competenties, maar dingen die je op de werkvloer kunt waarnemen:
- Controleert de medewerker feiten voordat AI-output wordt verstuurd?
- Schrijft de medewerker prompts extern voor in een document?
- Heeft de medewerker een werkende AI-werkomgeving met contextdocumenten?
De gedetailleerde gedragstabellen vind je in elk van de drie verdiepingsartikelen.
## Van inzicht naar implementatie
Je weet nu welke drie vaardigheden het verschil maken. De vraag is: hoe breng je die bij je team?
### Onze aanpak
Bij Copilot Academy werken we met een gestructureerd programma dat de drie vaardigheden opbouwt in logische volgorde:
1. AI Begrip opbouwen: begrijp de mogelijkheden en beperkingen
2. Promptvaardigheden ontwikkelen: leer communiceren met AI
3. AI-werkomgeving inrichten: maak AI structureel onderdeel van het werk
Elke stap bouwt voort op de vorige. En elke stap levert meetbaar resultaat: van observeerbaar gedrag tot concrete tijdsbesparing.
Na het volledige programma zien we dat deelnemers AI structureel blijven gebruiken en de geleerde vaardigheden toepassen in hun dagelijkse werk.
Wil je weten hoe dit er voor jouw organisatie uit kan zien? Bekijk het [AI Skills Programma](/ai-skills-programma/) of [plan een gesprek](/contact/) met een van onze trainers.
## Copilot Excel & Data Training
> Leer AI inzetten voor data-analyse en Excel-werk. Van formules genereren tot datasets analyseren en visualisaties maken.
**Prijs:** €2.450 per groep · **Duur:** 3 uur · **Formaat:** blended
**URL:** https://copilot-academy.nl/training/copilot-excel-ai-training/
## AI voor data-analyse en Excel-werk
Excel is voor veel professionals het belangrijkste werkinstrument. Maar complexe formules opbouwen, datasets opschonen en rapporten samenstellen kost uren. Met AI automatiseer je het routinewerk en focus je op de analyse zelf.
### Waar AI het verschil maakt in Excel
In deze training leer je AI inzetten voor de taken waar je nu de meeste tijd aan kwijt bent:
- **Formules genereren**: beschrijf in gewone taal wat je wilt berekenen en laat AI de formule bouwen. Van geneste IF-statements tot complexe VLOOKUP-combinaties.
- **Data opschonen**: inconsistente notaties, ontbrekende waarden en duplicaten. AI helpt je datasets in minuten op orde brengen in plaats van uren.
- **Analyses uitvoeren**: draaitabellen opzetten, trends identificeren en uitschieters signaleren. Je leert AI de juiste vragen stellen over je data.
- **Visualisaties maken**: van ruwe cijfers naar heldere grafieken. AI kiest het juiste grafiektype en formatteert het resultaat.
### Copilot in Excel vs. ChatGPT
Beide tools zijn bruikbaar voor datawerk, maar op verschillende manieren. Copilot werkt direct in je spreadsheet en kan formules invoegen, kolommen toevoegen en grafieken genereren zonder dat je Excel verlaat. ChatGPT is sterker in het uitleggen van complexe formules, het schrijven van VBA-macro's en het analyseren van data die je als tekst deelt.
In de training leer je wanneer je welke tool inzet en hoe je ze combineert voor het beste resultaat.
### Hoe de training werkt
We werken zoveel mogelijk met jullie eigen data (geanonimiseerd waar nodig). Je doorloopt vier oefeningen: een dataset opschonen, een analyse uitvoeren, een rapport genereren en een bestaand spreadsheet optimaliseren. Elke oefening bouw je op met templates die je direct kunt hergebruiken.
### Wat je meeneemt
Je ontvangt een **formule-bibliotheek** met de meest gebruikte AI-gegenereerde formules per categorie (financieel, HR, operations) en **analyse-templates** die je als startpunt gebruikt voor eigen projecten.
Wil je eerst meer weten over hoe je [effectief prompts schrijft voor gestructureerd werk](/kennisbank/effectief-prompten-voor-teams/)? Het TCRF-framework dat we in dat artikel beschrijven, pas je ook toe in datawerk.
---
# Kennisbank
## Een webpagina kopiëren als platte tekst (voor AI)
> Cookiebanners, menu's, chatbots en advertenties. Een gewone webpagina kopiëren naar AI levert meestal rommel op. Twee manieren om er schone tekst van te maken.
**Auteur:** Casimir Morreau · **Datum:** 2026-05-12
**URL:** https://copilot-academy.nl/kennisbank/webpagina-naar-platte-tekst-voor-ai/
## Het probleem: een webpagina is geen tekst
Je kopieert een pagina van een bedrijfssite, plakt het in Copilot en vraagt om een samenvatting. Het antwoord begint met "Skip to main content" en eindigt met de cookieverklaring. De helft van wat je geplakt hebt is menu, footer, chatbotknop en advertentietekst.
Een taalmodel ziet geen pagina. Het ziet een muur van tekst zonder onderscheid tussen inhoud en interface. Hoe minder ruis je meegeeft, hoe beter het antwoord. Hier zijn twee manieren om alleen de inhoud op te halen.
## Optie 1: Immersive Reader in Microsoft Edge
In Edge zit een knopje dat de pagina ontdoet van alles wat geen tekst is. Geen menu's, geen banners, geen reclame. Alleen de leesinhoud.
1. Open de pagina in Edge
2. Klik op het boekicoon in de adresbalk (of druk op F9)
3. Kies "Immersive reader"
4. Selecteer alles (Cmd+A of Ctrl+A), kopieer, plak in je AI

Wat je terugkrijgt is de pagina zonder opmaak en zonder interface. Werkt op de meeste nieuwspagina's, kennisbanken en artikelen. Op heel zware webapps (dashboards, formulieren) verschijnt de knop soms niet, omdat de pagina geen duidelijke "leestekst" heeft.
## Optie 2: defuddle.md voor de adresbalk
Soms wil je geen knoppen klikken, en soms gebruik je geen Edge. Dan kun je een truc toepassen die in elke browser werkt: plak `https://defuddle.md/` voor de URL.
Dus van:
```
https://www.bngbank.nl/over-bng
```
Maak je:
```
https://defuddle.md/https://www.bngbank.nl/over-bng
```

Wat terugkomt is markdown: de tekst met koppen, opsommingen en links, zonder de rest. Bovenaan staan handige metadata (titel, bron, taal, woordaantal) die je gewoon mee kan kopiëren naar je AI.
Twee alternatieven die hetzelfde doen:
- `https://markdown.new/[url]`
- `https://r.jina.ai/[url]`
Welke je kiest is smaak. Defuddle is iets schoner in zijn output, Jina werkt soms beter op pagina's die JavaScript nodig hebben om te laden.
## Wanneer welke methode
| Situatie | Methode |
|----------|---------|
| Eén pagina, snel iets samenvatten | Immersive Reader |
| Achter een login of paywall | Immersive Reader (je bent al ingelogd) |
| Geen Edge bij de hand | defuddle.md voor de URL |
| Pagina laadt met JavaScript | r.jina.ai voor de URL |
| Je wilt de tekst opslaan als markdown | defuddle.md (bestand opslaan) |
## Waarom dit ertoe doet
Veel teams plakken pagina's letterlijk in Copilot of ChatGPT en vragen zich daarna af waarom het antwoord rommelig is. De input is rommelig. Een taalmodel maakt geen onderscheid tussen "inhoud van de pagina" en "knop in de navigatie", tenzij je dat onderscheid voor het model maakt.
Dit hoort bij [contextbeheer](/kennisbank/context-management-ai-werkomgeving/): de inhoud die je AI geeft is even bepalend voor het antwoord als de vraag die je stelt. Schone input, beter resultaat.
Hetzelfde principe waarom je [PDF's beter omzet naar platte tekst](/kennisbank/waarom-pdfs-niet-werken-met-ai/) voordat je ze aan AI geeft, geldt voor webpagina's. Het kost je tien seconden. Het scheelt je een onbruikbaar antwoord.
## Je AI-kennisbank opbouwen: van losse documenten naar een werkend geheugen
> AI weet niets over je organisatie. Een kennisbank verandert dat. Maar de meeste documenten zijn niet AI-ready. Zo maak je ze klaar.
**Auteur:** Casimir Morreau · **Datum:** 2026-03-04
**URL:** https://copilot-academy.nl/kennisbank/ai-kennisbank-opbouwen/
## AI heeft geen geheugen van jouw organisatie
Een taalmodel heeft miljarden teksten gelezen. Het weet wat klantdata is, hoe marketingcampagnes werken en wat een goede strategie er ongeveer uit ziet. Maar het weet niets over *jouw* klantdata, *jouw* campagnes of *jouw* strategie.
Elke keer dat je een nieuwe chat opent, begint het model met een blanco lei. Het kent je interne jargon niet. Het weet niet dat klant X een uitzonderingskorting krijgt, dat jullie marketingteam onderscheid maakt tussen merk A en merk B, of dat jullie feedbackresultaten van vorig kwartaal een verschuiving lieten zien in doelgroepgedrag.
Dat is het fundamentele probleem. En de oplossing is geen betere prompts schrijven. De oplossing is een **kennisbank**: een gestructureerde verzameling documenten die het taalmodel voorziet van alles wat het mist.
## Wat is een AI-kennisbank precies?
De definitie is kort: **alle informatie die een taalmodel nodig heeft, maar niet kent.**
Dat klinkt breed, en dat is het ook. In de praktijk gaat het om dingen als: wie jullie zijn en welke merken onder jullie vallen. Doelstellingen, KPI's, doelgroepomschrijvingen. Campagneresultaten en A/B-testuitkomsten. Hoe jullie een campagne opzetten, welke stappen je altijd doorloopt. Prijslijsten, klantprofielen, kortingsafspraken. En misschien het meest waardevolle: de learnings van de ene campagne die je bij de volgende wil meenemen.
Het gaat niet om een databasedump. Het gaat om de kennis die je team in z'n hoofd heeft, maar die nergens expliciet opgeschreven staat. Elke organisatie heeft dit: impliciete afspraken, ongeschreven regels, nuances die je na drie maanden vanzelf oppikt. Die kennis moet je expliciet maken, want een taalmodel pikt het niet vanzelf op.
## Waarom je documenten niet AI-ready zijn
Hier zit een pijnpunt waar de meeste teams tegenaan lopen. Je hebt bergen aan informatie: strategiedecks in Google Slides, campagnerapporten als PDF, tarieven in Excel, projectplannen in PowerPoint. Het probleem: die formaten zijn gemaakt voor mensen, niet voor AI.
### PDF: onbetrouwbaar voor gestructureerde data
Een [PDF lijkt overzichtelijk voor ons](/kennisbank/waarom-pdfs-niet-werken-met-ai/). Mooi opgemaakt, tabellen netjes uitgelijnd, logo in de hoek. Maar voor een taalmodel is een PDF een ramp. Tabellen verschuiven, kolommen lopen door elkaar, nummers verspringen van de ene naar de andere pagina. Het model hallucineert getallen die het niet goed kan lezen. Prijzen, percentages, klantnummers: precies de data waar het om gaat.
### Platte tekst: een wereld van verschil
Zet datzelfde document om naar platte tekst met koppen en structuur (markdown of een Google Doc), en de nauwkeurigheid gaat drastisch omhoog.
Waarom? Taalmodellen zijn getraind op tekst. Ze begrijpen koppen, opsommingen, tabellen in tekstformaat. Ze hoeven niet te raden waar een kolom ophoudt en de volgende begint. De inhoud is wat telt, niet de opmaak.
### De praktische aanpak
Je hoeft niet alles om te zetten. Focus op je **kerndocumenten**: de 10-15 bestanden die je het vaakst gebruikt. De strategie van je merk, je campagneblauwdruk, je tarieven, je doelgroepomschrijving. Die maak je AI-ready. De rest gooi je er gewoon in als losse bijlage als je het nodig hebt.
Omzetten kan op meerdere manieren. Heb je Google Slides? Laat Gemini de slides lezen en omzetten naar gestructureerde tekst. Het model haalt de tekst eruit en beschrijft ook wat het op visuele elementen ziet (grafieken, schema's, foto's). Heb je een PDF? Upload hem en vraag om omzetting naar "rauwe markdown". Maar beter nog: pak het originele bronbestand (het Word-document, de Google Sheet) en werk daarmee. Excel en Sheets exporteer je naar CSV of kopieer je als tekst. Tabellen in platte tekst werken prima.
**Tip**: zet Google Docs op "pageless" (via Bestand > Pagina-instelling). Je hebt geen paginascheiding nodig. Het gaat om de tekst, niet om hoe het eruitziet op papier.
## Twee soorten documenten die je nodig hebt
In de praktijk merk je al snel dat je twee verschillende types documenten bouwt. Ze worden vaak door elkaar gehaald, maar het onderscheid is belangrijk.
### 1. Contextdocumenten
Een [contextdocument](/kennisbank/context-management-ai-werkomgeving/) beschrijft de *inhoud*: wie zijn jullie, wat doen jullie, hoe werken jullie. Het is de kennis zelf.
Voorbeelden:
- "Dit is merk X. De doelgroep is Y. De strategie voor 2026 richt zich op Z. Onze KPI's zijn..."
- "Dit is ons campagneteam. Collega A doet social, collega B doet print. Onze planning loopt per kwartaal."
- "Klant A krijgt 20% korting. Dit is besloten in Q3 2025 door [naam], reden: meerjarencontract."
Dat laatste punt is belangrijk. Veel organisaties documenteren *wat* ze besloten hebben, maar niet *waarom*. Die korting staat ergens in een spreadsheet, maar de reden staat nergens. Dan gaat het taalmodel ervan uit dat alle klanten 20% korting krijgen. Dat soort fouten wil je voorkomen.
### 2. Wegwijzerdocumenten
Een wegwijzerdocument beschrijft de *structuur*: wat staat waar, hoe is de kennisbank georganiseerd, en welk document is leidend als er tegenstrijdigheden zijn.
Dit is wat in Claude een `CLAUDE.md`-bestand heet, en in Gemini een soortgelijke functie vervult. Het vertelt het model: "In map 1 vind je klantdata. In map 2 vind je tarieven. Het document `tarieven-2026.md` is de single source of truth voor prijzen."
**Single source of truth** is een begrip dat je gaat gebruiken. Als op drie plekken in je kennisbank iets over trainingslengte staat (twee keer drie uur, drie keer twee uur, twee keer 2,5 uur), dan moet je ergens vastleggen welk document de waarheid is. Anders kiest het model willekeurig en krijg je inconsistente output.
## Je blijft aan het stuur
Er is veel hype over AI-agents die volledig zelfstandig werken. E-mail beantwoorden, campagnes opzetten, analyses draaien. In de praktijk werkt het anders.
De werkwijze die wél werkt, zit in het midden: **jij blijft in de loop**. Het model doet voorwerk: door je kennisbank zoeken, relevante documenten ophalen, een eerste versie opstellen. Maar jij beoordeelt het resultaat en beslist wat ermee gebeurt.
Dat heet "agentic" werken. Je geeft het model een opdracht, het gaat zelfstandig aan de slag (doorzoekt documenten, maakt subchats aan, vergelijkt bronnen), en komt terug met een voorstel. Jij zegt ja, nee, of pas dit aan. Het model gaat weer verder. Zo werk je samen.
Dit is ook precies waar de nuance zit. Een taalmodel kan een campagneanalyse maken, maar het kan niet beoordelen of die analyse klopt in jullie specifieke context. Het kan een voorstel schrijven, maar het weet niet of de toon past bij die ene klant die altijd formeler aangesproken wil worden. Die beoordeling blijft bij jou.
En dat is geen tekortkoming. Dat is hoe kenniswerk werkt. Bij software kan AI bouwen, testen, fouten opsporen en opnieuw proberen. Bij consumenteninzichten of campagnestrategieën zit de waarde in menselijk oordeelsvermogen. Je baan verandert, maar verdwijnt niet.
## Zo begin je: vier stappen
### Stap 1: Inventariseer je kerndocumenten
Welke 10-15 documenten gebruik je het vaakst? Denk aan: merkstrategie, campagneblauwdruk, doelgroepomschrijving, tarieven, learnings van afgelopen kwartaal, teamrolverdeling.
### Stap 2: Maak een contextdocument
Begin met één document dat beschrijft wie jullie zijn en wat jullie doen. Gebruik het als startpunt bij elke AI-interactie. Je kunt dit handmatig schrijven, of je laat het model je interviewen: plak je strategieslides erin en vraag om een gestructureerd contextdocument op basis daarvan.
Belangrijk: ga er daarna met chirurgische precisie doorheen. Het model maakt een prima eerste versie, maar als er een fout in je basisdocument zit, plant die zich voort in alles wat je ermee doet. Laat de mensen die erover gaan het document checken.
### Stap 3: Zet kerndocumenten om naar platte tekst
Neem je strategiedeck, je campagnerapport, je tarieven. Zet ze om van PDF of Slides naar gestructureerde tekst. Koppen, subkoppen, opsommingen. Geen opmaak, geen logo's, geen paginanummers. De inhoud telt.
### Stap 4: Organiseer en markeer
Maak een mappenstructuur. Geef elke map een naam die beschrijft wat erin zit. Schrijf een wegwijzerdocument dat uitlegt hoe de kennisbank is opgebouwd. Markeer per onderwerp welk document de single source of truth is.
## Veelgemaakte fouten
De meeste teams beginnen te groot. Ze willen alles in één keer omzetten. Doe dat niet. Begin met één contextdocument en vijf kerndocumenten. Bouw uit over tijd.
Een tweede klassieke fout: PDF's erin gooien en hopen dat het werkt. Het werkt, maar niet goed genoeg voor werk waar nauwkeurigheid telt. Zet je kerndocumenten om.
Verder vergeten teams vaak de nuance. Het model leest wat je het geeft. Als nergens staat waarom een beslissing genomen is, weet het model dat ook niet. Documenteer het *wat* én het *waarom*.
Zet ook elk contextdocument op read-only, behalve voor de eigenaar. Als iedereen erin kan bewerken, verdwijnt de betrouwbaarheid.
En tot slot: ruim tegenstrijdigheden op. Als op twee plekken verschillende dingen staan over trainingslengte of tarieven, gaat het model struikelen. Wijs een single source of truth aan.
## Dit is geen automatisering
Het is verleidelijk om een kennisbank te zien als een stap richting automatisering. Dat is het niet. Een kennisbank is een bron van waarheid. Hoe je werkt verandert (sneller, breder, met betere eerste versies), maar wat je doet en waarom je het doet, blijft hetzelfde.
Je verantwoordelijkheid verschuift van alles zelf uitzoeken naar het beoordelen en bijsturen van wat het model oplevert. Je rijkwijdte wordt groter. Je kunt meer. Maar het blijft jouw expertise die bepaalt of de output klopt.
De investering zit niet in de tool. Die heb je waarschijnlijk al. De investering zit in het opschrijven van wat je team weet. Dat kost tijd, en het is niet het spannendste werk. Maar elk uur dat je erin stopt, verdien je dubbel terug bij elk volgend project dat je met AI oppakt.
## Waarom AI je altijd gelijk geeft (en hoe je dat gebruikt)
> AI is getraind om behulpzaam te zijn, niet om eerlijk te zijn. Dat maakt het een ja-knikker. Maar als je snapt hoe dat werkt, kun je het in je voordeel gebruiken.
**Auteur:** Casimir Morreau · **Datum:** 2026-03-04
**URL:** https://copilot-academy.nl/kennisbank/waarom-ai-altijd-gelijk-geeft/
## De ja-knikker op je bureau
Twee mensen leggen dezelfde ruzie voor aan ChatGPT. Beiden krijgen gelijk. Niet omdat het model liegt, maar omdat het is gebouwd om behulpzaam te zijn voor degene die de vraag stelt.
Dat is sycophancy. Het woord klinkt academisch, maar het gedrag is heel herkenbaar. AI wil je helpen. Het wil dat je tevreden bent met het antwoord. En dus stuurt het mee met de richting die jij al aangaf in je vraag.
Voor een brainstorm is dat prima. Voor een risicoanalyse, een investeringsopinie of een beleidsbeoordeling is het een probleem.
## Hoe je AI onbewust stuurt
De meeste sturing gebeurt onbewust, in je woordkeuze. Een paar voorbeelden.
*"Zou het een goed idee zijn om..."* Je hebt al "goed" gezegd. Het model pikt dat op en bevestigt. Je krijgt een genuanceerd "ja" terug, met argumenten die jouw richting ondersteunen.
*"Kun je bevestigen dat..."* Je vraagt om bevestiging. Het model geeft bevestiging.
*"Ik denk dat we moeten..."* Je hebt al een voorkeur uitgesproken. Het model volgt.
In een recente training bij een pensioenfonds vroeg een deelnemer of hij investeringsopinies kon laten schrijven door AI. Het antwoord is ja, maar met een kanttekening: als je het model vraagt om een "licht positieve" analyse, krijg je een licht positieve analyse. Vraag je om een "licht negatieve", krijg je die. Het model spiegelt jouw framing.
Dat is geen fout. Zo is het gebouwd. Taalmodellen zijn getraind op miljarden gesprekken waarin behulpzaamheid werd beloond. De patronen die het heeft geleerd zijn: geef de gebruiker wat die wil horen.
## Elk model heeft een persoonlijkheid
Er zit nog een laag bovenop. Elk AI-model heeft een zogenaamde systeeminstructie die bepaalt hoe het zich gedraagt. En die instructies zijn niet neutraal.
ChatGPT is getraind om persoonlijk te zijn, coachend, bemoedigend. Het geeft je complimenten. "Wat een goed idee, Joyce!" "Dat heb je scherp gezien!" Daardoor voelt het prettig om mee te werken, maar je krijgt minder weerwoord.
Copilot heeft een zakelijker systeeminstructie. Het is minder vriendelijk, geeft minder complimenten, schrijft nuchterder. Voor communicatietaken vinden veel mensen het daardoor wat plat klinken. Voor analytisch werk is die zakelijkheid juist een voordeel.
Claude zit daar ergens tussenin: minder complimenteus dan ChatGPT, maar met meer neiging om nuances en tegenargumenten te benoemen.
Het punt: "neutraal" bestaat niet bij AI. Elk model heeft een toon en een neiging. Als je dat weet, kun je erop corrigeren. Als je het niet weet, neem je de output voor waarheid aan.
## Elke keer een ander antwoord
Er is nog iets dat veel mensen verrast. Stel dezelfde vraag twee keer en je krijgt twee verschillende antwoorden. Niet omdat het model twijfelt, maar omdat het werkt met kansberekening. Het kiest steeds het meest waarschijnlijke volgende woord, maar bij gelijke kansen maakt het een willekeurige keuze.
Vraag je "het beste huisdier is een..." dan krijg je de ene keer hond, de andere keer kat, soms konijn. Vraag je "de hoofdstad van Frankrijk is..." dan krijg je 99,99% van de tijd Parijs, want daar is geen twijfel over in de trainingsdata.
Voor feitelijke vragen maakt dat weinig uit. Maar voor subjectieve taken (een samenvatting, een opinie, een analyse) krijg je elke keer een iets andere versie. Net als wanneer je twee collega's dezelfde vergadering laat samenvatten.
Veel mensen vinden dat frustrerend. Maar het is juist een kracht. Je kunt dezelfde vraag drie keer stellen en dan de beste versie kiezen. Of aan het model vragen: welke van deze drie antwoorden is het sterkst?
## Hoe je sycophancy in je voordeel gebruikt
Als je eenmaal snapt dat AI meestuurt met jouw richting, kun je dat bewust inzetten. In plaats van één vraag te stellen en het antwoord te accepteren, stel je dezelfde vraag vanuit meerdere perspectieven.
### Wissel van perspectief
Stel dezelfde vraag vanuit meerdere rollen:
> Analyseer dit investeringsvoorstel vanuit het perspectief van een risicomijdend pensioenfonds.
> Analyseer hetzelfde voorstel vanuit het perspectief van een agressieve hedgefund-manager.
> Welke risico's zou een toezichthouder als DNB in dit voorstel zien?
Drie perspectieven, drie analyses. Samen geven ze je een completer beeld dan één "neutraal" antwoord ooit zou doen.
### Vraag om tegenspraak
> Ik denk dat we dit project moeten doorzetten. Geef me 5 redenen waarom dat een slecht idee zou zijn.
Door expliciet om tegenargumenten te vragen, doorbreek je de neiging tot meeknikken. Het model kan sterke tegenargumenten formuleren, maar doet dat alleen als je erom vraagt.
### Geef een kritische rol
> Je bent een kritische reviewer die zwakke punten in argumenten zoekt. Bekritiseer dit voorstel. Wees streng.
Door een [rol mee te geven](/kennisbank/effectief-prompten-voor-teams/) die expliciet kritisch is, verschuif je de toon van het hele gesprek. Het model gaat niet meer pleasen, het gaat prikken.
## De vuistregels
Drie dingen om te onthouden:
Stel nooit een suggestieve vraag als je een eerlijk antwoord wilt. Niet "Is dit een goed plan?" maar "Wat zijn de sterke en zwakke punten van dit plan?" Hoe neutraler je vraag, hoe neutraler het antwoord.
Gebruik meerdere perspectieven voor belangrijke beslissingen. Eén AI-antwoord is een mening. Drie AI-antwoorden vanuit verschillende rollen geven je een spectrum. Dat spectrum is bruikbaar.
Vertrouw je eigen expertise. AI is snel, breed en geduldig. Maar jij kent je organisatie, je klant en je context. Als een AI-antwoord "niet lekker voelt", is dat gevoel waarschijnlijk terecht. De [VAK-check](/kennisbank/ai-begrip-hallucinaties/) (Verifieerbaar, Accuraat, Kloppend) helpt je om dat gevoel om te zetten in een systematische controle.
## AI is geen orakel
De meeste teleurstelling met AI komt niet uit slechte technologie, maar uit verkeerde verwachtingen. Mensen verwachten een neutraal, objectief antwoord. Wat ze krijgen is een statistisch waarschijnlijk antwoord dat is geoptimaliseerd voor tevredenheid.
Zodra je dat accepteert, verandert hoe je met het model werkt. Je stopt met één vraag stellen en het antwoord kopiëren. Je begint het te gebruiken als een gesprekspartner die je vanuit meerdere hoeken laat kijken naar hetzelfde probleem. Geen orakel dat de waarheid spreekt, wel een spiegel die je laat zien wat je zelf misschien over het hoofd ziet.
Dat kun je leren.
Lees verder: [AI Begrip: Waarom medewerkers moeten snappen hoe AI werkt](/kennisbank/ai-begrip-hallucinaties/)
## Waarom PDF's niet werken met AI (en wat je eraan doet)
> PDF's zijn gemaakt voor mensen, niet voor taalmodellen. Tabellen verschuiven, kolommen lopen door elkaar, cijfers worden verzonnen. Zo voorkom je dat.
**Auteur:** Casimir Morreau · **Datum:** 2026-03-04
**URL:** https://copilot-academy.nl/kennisbank/waarom-pdfs-niet-werken-met-ai/
## Het ziet er goed uit. Maar de AI leest het verkeerd.
Je uploadt een campagnerapport als PDF naar Gemini of ChatGPT. Mooie tabellen, nette kolommen, logo in de hoek. Je vraagt om een samenvatting van de kwartaalcijfers. Het antwoord klinkt overtuigend, de zinnen lopen, het formaat klopt. Maar de cijfers kloppen niet.
Dat is het verraderlijke aan PDF's en AI. Het model geeft je geen foutmelding. Het doet zijn best met wat het krijgt, en als het iets niet goed kan lezen, vult het de gaten zelf in. Dat heet [hallucinatie](/kennisbank/ai-begrip-hallucinaties/), en het gebeurt vaker dan je denkt.
## PDF is gemaakt voor ogen, niet voor taalmodellen
Het PDF-formaat stamt uit de vroege jaren negentig. Adobe ontwikkelde het om documenten te delen die er overal identiek uitzagen: eerst op papier, later op scherm. De Amerikaanse belastingdienst was een van de eerste grote gebruikers: formulieren die er bij elke ontvanger precies hetzelfde uitzagen, zonder ze te printen en te posten. Sindsdien is PDF de standaard geworden voor iedereen die een betrouwbaar document nodig heeft: advocaten, overheden, uitgevers, pensioenfondsen.
Maar onder de motorkap is een PDF geen tekst. Het is een verzameling instructies voor het *tekenen* van tekst op een pagina: lettercoördinaten, fontkeuzes, posities in pixels.
Een taalmodel leest geen pixels. Het leest tekst. Om iets met een PDF te doen, moet het model eerst de tekst eruit halen via OCR (optical character recognition). En daar gaat het mis.

## Waar het concreet misgaat
### Tabellen
Dit is het grootste probleem. Een PDF-tabel ziet er voor ons helder uit: rijen, kolommen, getallen netjes uitgelijnd. Maar voor een taalmodel zijn het losse tekstelementen zonder structuur. Kolommen lopen door elkaar, rijen verschuiven, een getal dat bij "Q3" hoort wordt gekoppeld aan "Q2".

In een recente training lieten we een pensioendocument zien met afkoopcijfers per leeftijdsgroep. Vijf kolommen, tientallen rijen. Voor ons helder. Het taalmodel haalde de kolommen door elkaar en gaf bedragen terug die bij de verkeerde leeftijdsgroep hoorden. Niemand die dat meteen ziet als je het antwoord niet narekent.
### Kolommen en layout
Veel rapporten en academische papers gebruiken twee kolommen. OCR leest van links naar rechts en combineert tekst uit de linker- en rechterkolom tot één onleesbare brij.
Hetzelfde probleem speelt bij paginaovergangen. Een tabel die doorloopt van pagina 10 naar pagina 11 is voor ons één geheel. Voor het model zijn het twee losse fragmenten. De koptekst verdwijnt, de context breekt af.
### Visuele elementen
Een staafdiagram in een PDF is voor ons in één oogopslag duidelijk. Een taalmodel kan er weinig mee. Het ziet de assen niet, leest de labels verkeerd en mist de onderlinge verhoudingen. Organogrammen en flowcharts zijn nog lastiger: het model ziet losse tekstvakken, maar begrijpt niet hoe ze met elkaar verbonden zijn.

En dan zijn er nog de scans. Gescande documenten met slechte resolutie, scheve tekst of handgeschreven aantekeningen in de marge. Het model doet zijn best, maar de foutmarge is groot.
## Waarom dit niet snel opgelost wordt
Je zou verwachten dat dit een opgelost probleem is. Taalmodellen kunnen code schrijven, wiskundige bewijzen leveren en in meerdere talen vertalen. Maar PDF's lezen? Daar worstelen ze mee.
Het kernprobleem gaat dieper dan slechte OCR. OCR herkent tekst, maar begrijpt de *redactionele structuur* van een document niet. Een kop, een voetnoot, een bijschrift bij een grafiek: voor ons is het verschil vanzelfsprekend. Voor een model zijn het stukjes tekst op een pagina, zonder hiërarchie. Zolang het om lopende tekst gaat, werkt dat prima. Maar zodra er tabellen, formulieren of meerdere kolommen in beeld komen, valt de structuur weg.
Er wordt aan gewerkt. Een nieuwe generatie gespecialiseerde modellen pakt PDF's aan in meerdere stappen: eerst het document opdelen in regio's (koppen, tabellen, afbeeldingen, voetnoten), dan elke regio doorsturen naar een apart model dat getraind is op precies dat type element. Die aanpak is vergelijkbaar met hoe zelfrijdende auto's werken: eerst de omgeving segmenteren (auto, voetganger, wegmarkering), dan per object beslissingen nemen. Grafieken worden zo omgezet naar spreadsheets, handgeschreven aantekeningen worden ontcijferd, en tabellen houden hun kolommen.
Waarom investeren bedrijven hier nu pas serieus in? Omdat AI-ontwikkelaars ontdekten dat PDF's een enorme, onbenutte bron van hoogwaardige data zijn. Overheidsrapporten, studieboeken, wetenschappelijke papers, octrooien: het zit allemaal in PDF. Onderzoekers schatten dat er biljoenen tokens aan trainingsdata in PDF's opgesloten zitten. Dat maakt het probleem ineens commercieel interessant.
De resultaten worden beter. Maar het blijft een probabilistisch systeem: het model *gokt* wat de structuur is. In 98% van de gevallen gaat dat goed. Die laatste 2% is precies de tabel met je kwartaalcijfers, het formulier met handgeschreven aantekeningen, de scan die net iets scheef staat. En dan zijn er de randgevallen waar niemand op rekent: PDF's die andere PDF's bevatten, juridische documenten met passages die soms onderstreept en soms doorgestreept zijn, faxen van medische formulieren waar artsen overheen hebben gekrabbeld.
PDF als formaat gaat ook niet weg. De zoektrend stijgt elk jaar gestaag, zonder uitzondering. Er is simpelweg geen ander formaat dat doet wat PDF doet: een document dat er voor elke ontvanger identiek uitziet, ongeacht apparaat, browser of tijdstip. Een PDF uit 1995 opent vandaag nog precies zoals bedoeld. Overheden, advocaten, uitgevers, pensioenfondsen: ze zijn er allemaal afhankelijk van. De hoeveelheid PDF's groeit. Het probleem wordt niet kleiner.
## Wat je er zelf aan doet
De oplossing is simpeler dan je denkt. Je hoeft niet te wachten op betere modellen. Je moet je kerndocumenten omzetten.
### Gebruik het bronbestand
Heb je het originele Word-document, de Google Sheet of de Google Slides? Gebruik dat. Altijd. Het bronbestand bevat de structuur die een PDF kwijtraakt. Pas als je geen bronbestand hebt, val je terug op de PDF.
### Zet om naar platte tekst
Kopieer de inhoud van je document naar een Google Doc of een markdown-bestand. Koppen, subkoppen, opsommingen, tabellen in tekstformaat. Geen opmaak, geen logo's, geen paginanummers. Het gaat om de inhoud.
Voor Google Docs: zet de pagina-instelling op "pageless" (Bestand > Pagina-instelling). Zonder pagina's werkt het als een eindeloos notitievel, dat is precies wat een taalmodel nodig heeft.
### Laat AI het omzetten
Heb je een slide deck van 50 pagina's? Upload het naar Gemini en vraag: "Zet dit om naar gestructureerde tekst in markdown. Beschrijf ook wat je op visuele elementen ziet." Het model haalt de tekst eruit en maakt een omschrijving van grafieken en foto's. Het resultaat check je, maar het bespaart je uren handwerk.
### Tabellen apart behandelen
Tabellen zijn het kwetsbaarst. Kopieer ze uit Excel of Sheets als platte tekst, of exporteer als CSV. Een tabel in CSV-formaat leest een taalmodel foutloos. Dezelfde tabel in een PDF is onvoorspelbaar.
### Werk in het Microsoft-ecosysteem
Gebruik je Microsoft 365 met Copilot? Dan omzeil je het PDF-probleem grotendeels. Copilot leest Word-, Excel- en PowerPoint-bestanden rechtstreeks via Microsoft Graph, inclusief de oorspronkelijke structuur. Geen OCR, geen gokwerk. Dat is een van de redenen waarom werken vanuit bronbestanden zo veel betrouwbaarder is dan werken vanuit een PDF-export.
## Wanneer een PDF wél prima is
Niet alles hoeft omgezet. PDF's werken goed genoeg voor:
- Lopende tekst zonder tabellen (een beleidsdocument, een rapport in proza)
- Brainstormen en globale samenvattingen (waar exacte cijfers niet kritiek zijn)
- Documenten die je eenmalig raadpleegt (niet als onderdeel van je vaste kennisbank)
De vuistregel: als je het antwoord niet zou narekenen, is een PDF prima. Als er geld, percentages of klantnamen in staan, zet dan om.
## Het kost een middag, het bespaart je maanden
De meeste teams die we trainen hebben 10 tot 15 kerndocumenten: strategieplannen, tarieven, campagneblauwdrukken, doelgroepomschrijvingen. Die documenten zet je één keer om naar platte tekst. Daarna gebruik je ze bij alles wat je met AI doet, bijvoorbeeld als onderdeel van je [AI-kennisbank](/kennisbank/ai-kennisbank-opbouwen/).
Dat omzetten kost een middag. Het alternatief is elke keer opnieuw met je vingers kruisen dat het model de PDF deze keer wel goed leest. Dat is geen werkwijze. Dat is hopen.
## AI Begrip: Waarom medewerkers moeten snappen hoe AI werkt
> Zonder basiskennis van AI maken medewerkers vermijdbare fouten. Leer over hallucinaties, de VAK-check en wanneer je AI wel en niet kunt vertrouwen.
**Auteur:** Casimir Morreau · **Datum:** 2026-02-02
**URL:** https://copilot-academy.nl/kennisbank/ai-begrip-hallucinaties/
## De hyperintelligente stagiair
Zie een AI-assistent als een briljante stagiair met een encyclopedisch geheugen, die soms dingen verzint. Niet uit kwade wil, maar omdat hij patronen herkent en daar conclusies aan verbindt die er niet zijn.
Dat is precies hoe AI-tools als Microsoft Copilot, ChatGPT en Claude werken. Ze zijn razend snel en indrukwekkend capabel. Maar ze hebben geen begrip van wat ze schrijven. Ze "weten" niet of iets klopt.
Voor HR- en L&D-professionals is dit het vertrekpunt van elke AI-training. Want zonder dit inzicht ontstaan twee problemen: medewerkers die AI blindelings vertrouwen, of medewerkers die na één slechte ervaring afhaken. Beide kosten je organisatie geld.
Dit artikel legt uit wat je team moet begrijpen over AI, en hoe je dat begrip meetbaar maakt.
## Hoe AI antwoorden genereert
### Voorspellen, niet denken
Een taalmodel zoals GPT-4 of Copilot werkt als een geavanceerde voorspellingsmachine. Het is getraind op miljarden teksten en leert patronen herkennen. Woord voor woord genereert het een antwoord door steeds het meest waarschijnlijke volgende woord te kiezen.
Vraag je: *"De hoofdstad van Frankrijk is..."* Dan voorspelt het model "Parijs" met 99% zekerheid. Niet omdat het weet dat Parijs de hoofdstad is, maar omdat in de trainingsdata "Frankrijk" en "Parijs" vrijwel altijd samen voorkomen.
### Geen begrip, geen geheugen
Dit heeft drie consequenties die je team moet kennen:
1. **AI begrijpt niet wat het schrijft.** Het herkent patronen, maar heeft geen concept van waarheid of betekenis.
2. **Elk antwoord is nieuw gegenereerd.** Zelfs dezelfde vraag kan een ander antwoord opleveren, want AI is non-deterministisch.
3. **AI kent je organisatie niet.** Het is getraind op algemene tekst van het internet, niet op jouw interne processen, klanten of bedrijfscultuur. Dat kun je oplossen met [contextbeheer](/kennisbank/context-management-ai-werkomgeving/).
Voor medewerkers betekent dit: AI is een hulpmiddel, geen betrouwbare informatiebron. Dat onderscheid moet iedereen in je team snappen.
## Hallucinaties: het grootste risico
AI-hallucinaties zijn antwoorden die overtuigend klinken maar feitelijk onjuist zijn. De beste modellen hallucineren in circa 2% van de antwoorden. Dat klinkt weinig, tot je beseft dat je team dagelijks tientallen AI-interacties heeft.
### De 4 types hallucinaties
**1. Feitelijke onjuistheden**
AI presenteert statistieken, datums of gebeurtenissen die niet kloppen. Een medewerker vraagt om marktcijfers en krijgt overtuigende percentages die nergens op gebaseerd zijn.
> *Voorbeeld: "De Nederlandse AI-markt groeide in 2025 met 34,7%." Dit klinkt precies genoeg om te geloven, maar het cijfer is verzonnen.*
**2. Verzonnen details**
Namen, producten of technische specificaties die niet bestaan maar aannemelijk klinken.
> *Voorbeeld: een medewerker vraagt Copilot om een referentie en krijgt "volgens het onderzoek van Van der Berg & Willemsen (2024, Universiteit Utrecht)". De onderzoekers en publicatie bestaan niet.*
**3. Logische fouten**
Rekenfouten of tegenstrijdige redeneringen die de conclusie onbetrouwbaar maken.
> *Voorbeeld: een financieel overzicht waar de deelbedragen niet optellen tot het totaal, maar de conclusie "binnen budget" luidt.*
**4. Fictieve bronnen**
Niet-bestaande onderzoeken, artikelen of experts die als referentie worden opgevoerd.
> *Voorbeeld: "Bron: McKinsey Digital Workplace Report 2025, pagina 47". Het rapport bestaat niet in die vorm.*
### Waarom hallucinaties gevaarlijk zijn in organisaties
In een kantooromgeving worden AI-gegenereerde teksten vaak direct doorgestuurd, in presentaties verwerkt of als basis voor beslissingen gebruikt. Als niemand controleert, verspreiden hallucinaties zich als feiten door de organisatie.
In onze trainingen zien we dat het merendeel van de deelnemers bij de nulmeting AI-output doorstuurt zonder controle.
## De VAK-check: drie vragen voor elke AI-output
Om hallucinaties te vangen voordat ze schade aanrichten, trainen wij medewerkers in de **VAK-check**. Drie vragen die je stelt voordat je AI-output gebruikt:
### V: Verifieerbaar
*Kan ik deze informatie controleren via een betrouwbare bron?*
Controleer feiten, cijfers en namen. Als AI een statistiek noemt, zoek de originele bron. Als AI een naam noemt, check of die persoon bestaat en of de context klopt.
**Vuistregel:** hoe specifieker het detail (een exact percentage, een datum, een naam), hoe groter de kans op een hallucinatie.
### A: Accuraat
*Kloppen de berekeningen en is de redenering logisch?*
Check of getallen optellen, of conclusies volgen uit de premissen, en of er geen tegenstrijdigheden in het antwoord zitten. AI is verrassend slecht in rekenen en logisch redeneren.
### K: Kloppend
*Komt dit overeen met wat ik als professional weet?*
Dit is de belangrijkste check. Jij bent de vakexpert, niet de AI. Als iets "niet lekker voelt" of afwijkt van wat je uit ervaring weet, vertrouw dan je eigen expertise.
**De VAK-check in de praktijk:**
| Situatie | V | A | K | Actie |
|----------|---|---|---|-------|
| Copilot vat een vergadering samen | ✓ Check namen aanwezigen | ✓ Check genoemde deadlines | ✓ Was ik erbij? Klopt dit? | Controleer en verstuur |
| AI schrijft een klantenmail | Geen feiten om te checken | ✓ Klopt de toon? | ✓ Past dit bij de relatie? | Review toon en inhoud |
| AI genereert marktcijfers | ✗ Bron opzoeken! | ✓ Tellen de delen op? | ✓ Realistisch? | Verifieer of vervang |
## Wanneer kun je AI vertrouwen? Het stoplichtmodel
Niet elke AI-taak vereist dezelfde mate van controle. Het stoplichtmodel helpt medewerkers inschatten hoeveel verificatie nodig is:
### Groen: laag risico
Taken waarbij fouten weinig impact hebben en makkelijk te corrigeren zijn.
- Brainstormen en ideeën genereren
- Eerste concepten schrijven die je zelf bewerkt
- Tekst samenvatten die je al kent
- Interne communicatie zonder feitelijke claims
**Controleniveau:** snel scannen, toon en stijl checken.
### Geel: gemiddeld risico
Taken waarbij fouten merkbaar zijn maar geen grote schade veroorzaken.
- E-mails naar klanten of partners
- Presentaties voor intern gebruik
- Vergadernotities en actiepunten
- Documenten die door anderen worden gelezen
**Controleniveau:** VAK-check toepassen, namen en feiten verifiëren.
### Rood: hoog risico
Taken waarbij fouten serieuze consequenties hebben.
- Juridische documenten of adviezen
- Financiële rapporten met cijfers
- Externe publicaties namens de organisatie
- Beslissingen op basis van AI-gegenereerde data
- Alles met privacy-gevoelige informatie
**Controleniveau:** volledige verificatie, laten reviewen door tweede persoon, bronnen checken.
**Voor managers:** als je team het stoplichtmodel consequent toepast, voorkom je de twee meest voorkomende AI-incidenten: het doorsturen van foutieve informatie en het delen van vertrouwelijke data met AI-tools.
## EU AI Act: wat je organisatie moet weten
Sinds 2025 stelt de EU AI Act eisen aan hoe organisaties AI inzetten. Voor de meeste kantooromgevingen is de directe impact beperkt: tools als Copilot vallen in de categorie "beperkt risico". Maar er zijn verplichtingen waar je organisatie rekening mee moet houden:
- Medewerkers en klanten moeten weten wanneer ze met AI-gegenereerde content te maken hebben (transparantie)
- Bij belangrijke beslissingen mag AI adviseren, maar een mens neemt de eindbeslissing (menselijk toezicht)
- De AI Act versterkt bestaande AVG-verplichtingen rond het gebruik van persoonsgegevens (data en privacy)
AI-begrip bij medewerkers is een eerste stap richting compliance. Wie begrijpt wat AI wel en niet kan, maakt betere keuzes over wanneer en hoe het wordt ingezet.
De meeste organisaties die we spreken hebben nog geen formeel AI-beleid. Dat verandert snel nu de EU AI Act in werking is getreden.
## Observeerbaar gedrag per niveau
Als HR- of L&D-professional wil je niet alleen weten *of* medewerkers AI begrijpen, maar ook *hoe goed*. Onderstaande tabel beschrijft concreet observeerbaar gedrag per niveau:
| | Starter | Basis | Vaardig |
|---|---------|-------|---------|
| **Vertrouwen & verificatie** | Weet dat AI fouten maakt, controleert incidenteel | Past de VAK-check toe op belangrijke output | Voorspelt waar AI moeite zal hebben, ontwerpt verificatieprocessen voor het team |
| **Taakselectie** | Gebruikt AI voor eenvoudige, laag-risico taken | Schat bewust in welke taken geschikt zijn (stoplichtmodel) | Bepaalt AI-strategie per projecttype, adviseert collega's |
| **Uitleg & overdracht** | Kan vertellen dat AI "soms fouten maakt" | Kan aan collega's uitleggen *waarom* AI soms foute informatie geeft | Geeft trainingen of workshops over AI-begrip aan teamleden |
| **Risicobewustzijn** | Deelt geen gevoelige data met publieke AI-tools | Kent het verschil tussen bedrijfs-AI en publieke tools, volgt richtlijnen | Draagt bij aan het AI-beleid van de organisatie |
**Hoe je dit meet:**
- Starter: intake-assessment of eerste zelfscan
- Basis: na de [AI Skills Basistraining](/training/microsoft-copilot-basis-training/) (portfolio-opdracht: VAK-check op eigen werkvoorbeeld)
- Vaardig: na de [AI Werkproces Training](/training/ai-werkproces/) en certificering
## Volgende stap: van begrip naar actie
AI begrijpen is de fundering. Maar begrip alleen levert nog geen betere output op. De volgende stap is leren om AI effectief aan te sturen, met gestructureerde instructies die consistent bruikbare resultaten opleveren.
Lees verder: **[Effectief Prompten: Van vage opdracht naar bruikbaar resultaat](/kennisbank/effectief-prompten-voor-teams/)**
Of ga terug naar het overzicht: **[De 3 AI-vaardigheden die je organisatie nodig heeft](/kennisbank/drie-essentiele-ai-skills/)**
## Contextbeheer: Hoe je AI leert je organisatie te begrijpen
> AI weet niets over je organisatie. Met contextdocumenten en een gestructureerde AI-werkomgeving krijg je output die direct bruikbaar is.
**Auteur:** Casimir Morreau · **Datum:** 2026-02-02
**URL:** https://copilot-academy.nl/kennisbank/context-management-ai-werkomgeving/
## Het contextprobleem
Je medewerker opent Copilot en typt: "Schrijf een voorstel voor thuiswerken." Het resultaat? Een generiek Amerikaans document over remote work, met verwijzingen naar wetgeving die niet bestaat in Nederland. Onbruikbaar.
Dit is het contextprobleem. AI-tools zijn getraind op miljarden teksten van het internet, maar ze weten niets over jouw organisatie. Ze kennen je klanten niet, je interne processen niet, je huisstijl niet, je CAO niet. Elke keer dat een medewerker een nieuwe chat opent, begint AI met een blanco lei.
Het verschil tussen een nieuwe medewerker en een ervaren collega? De ervaren collega kent de context. Diezelfde sprong kun je maken met AI, als je het de juiste informatie geeft.
Dit is de derde en misschien wel de meest onderschatte AI-vaardigheid: **contextbeheer**. Het vermogen om AI systematisch te voorzien van de informatie die het nodig heeft om output te leveren die past bij jouw specifieke situatie.
## Wat is een contextdocument?
Een contextdocument is een bestand dat achtergrondinformatie bevat die je aan AI meegeeft. Het is geen prompt, het is de *kennis* die achter de prompt zit.
Vergelijk het met het verschil tussen een briefing en een opdracht. De opdracht is: "Schrijf een klantenmail." De briefing is alles wat de schrijver moet weten om die mail goed te schrijven: wie is de klant, wat is de relatie, welke toon gebruiken we, wat is er eerder besproken.
### Types contextdocumenten
**Organisatiecontext**: bedrijfsprofiel (sector, omvang), huisstijl en tone of voice, interne termen en jargon.
**Teamcontext**: teamsamenstelling en rollen, lopende projecten, werkprocessen en procedures.
**Persoonlijke context**: je rol en verantwoordelijkheden, terugkerende taken, voorkeursstijl in communicatie.
**Taakspecifieke context**: klantprofielen, productinformatie, beleidsdocumenten, vergadernotities en projectdocumentatie.
## De AI-werkomgeving: drie mappen
In onze trainingen leren we medewerkers een gestructureerde AI-werkomgeving opzetten. Het principe is simpel: drie mappen die je AI-werk organiseren.
```
AI-werkomgeving/
├── Promptbibliotheek/ → Geteste, herbruikbare prompts per taaktype
├── Contextdocumenten/ → Organisatie-, team- en persoonlijke context
└── Projecten/ → Lopend werk, bronnen en AI-output
```
### Promptbibliotheek
Hier bewaar je prompts die je hebt getest en verfijnd. Niet als losse experimenten, maar als herbruikbare templates voor terugkerend werk. Een medewerker die wekelijks vergadernotities maakt, heeft één geteste prompt die elke keer werkt, in plaats van elke week opnieuw te improviseren.
### Contextdocumenten
Dit is het hart van contextbeheer. Je maakt een beperkt aantal documenten (vaak 3-5) die je herhaaldelijk meestuurt of koppelt aan je AI-tool. Eén keer goed opzetten bespaart wekelijks tijd.
### Projecten
Hier sla je lopend werk op: bronnen die je aan AI voert, tussenresultaten, en definitieve output. Zo voorkom je dat je steeds dezelfde informatie opnieuw moet invoeren.
**Het resultaat:** medewerkers die met een AI-werkomgeving werken, besteden minder tijd aan het herhalen van instructies en meer tijd aan het verfijnen van output.
Medewerkers met een ingerichte AI-werkomgeving besparen structureel tijd doordat ze instructies niet hoeven te herhalen.
## Van generieke naar organisatie-output
Het verschil dat context maakt, is dramatisch. Hieronder een voorbeeld uit de praktijk:
### Zonder context
**Prompt:** "Schrijf een voorstel voor hybride werken bij onze zorginstelling."
**Resultaat:**
- Generiek Amerikaans document over "remote work"
- Standaard kantoortermen, niet relevant voor zorg
- Verwijzing naar verouderde of niet-bestaande wetgeving
- Geen rekening met 24/7 diensten of patiëntveiligheid
### Met context
**Prompt:** "Schrijf een voorstel voor hybride werken voor onze zorginstelling."
**Contextdocument meegestuurd:**
- Organisatie: regionale zorginstelling, 1.200 medewerkers, 3 locaties
- CAO: CAO-Zorg met specifieke bepalingen over werktijden
- Situatie: 24/7 diensten, patiëntveiligheid heeft prioriteit
- Doelgroep: OR en directie
- Perspectief: HR-adviseur
**Resultaat:**
- Specifiek voor de Nederlandse zorgsector
- Correcte verwijzing naar CAO-Zorg voorwaarden
- Borging van continuïteit van zorg als uitgangspunt
- Praktisch implementatieplan per locatie
- Geschreven in taal die past bij OR en directie
Hetzelfde model, dezelfde vraag, maar een fundamenteel ander resultaat. Het verschil is uitsluitend de context.
## Herbruikbare templates: de prompt + context formule
De kracht van contextbeheer zit in herbruikbaarheid. In plaats van elke keer opnieuw alle informatie in te typen, combineer je een vaste prompt met een contextdocument.
### De formule
```
Startprompt (TAAK + ROL + FORMAT) + Contextdocument = Organisatie-specifieke output
```
### Voorbeeld: wekelijkse klantupdate
**Startprompt (bewaard in promptbibliotheek):**
> TAAK: Schrijf een beknopte klantupdate voor de accountmanager.
> ROL: Je bent een ervaren communicatieadviseur in de zakelijke dienstverlening.
> FORMAT: Max 200 woorden. Structuur: voortgang (3 bullets), aandachtspunten (2 bullets), volgende stap (1 zin).
**Contextdocument (bewaard in contextdocumenten):**
> Klant: [Bedrijfsnaam], sector: financieel, contactpersoon: [Naam] (afdelingshoofd operations).
> Relatie: bestaande klant sinds 2023. Toon: professioneel maar persoonlijk, gebruik voornaam.
> Lopend project: [Projectnaam], fase: implementatie, deadline: Q2 2026.
> Aandachtspunt: klant hecht aan transparantie over risico's.
**Input (wisselend per week):**
> Afgelopen week: [plak hier de relevante notities of actiepunten]
De startprompt en het contextdocument blijven gelijk. Alleen de input verandert. Resultaat: consistente, kwalitatieve output in een fractie van de tijd.
Wil je dieper in de promptstructuur duiken? Lees meer over de vier bouwstenen in ons artikel over [effectief prompten](/kennisbank/effectief-prompten-voor-teams/).
## Waarom contextbeheer AI-adoptie schaalbaar maakt
De eerste twee AI-vaardigheden ([AI begrijpen](/kennisbank/ai-begrip-hallucinaties/) en [effectief prompten](/kennisbank/effectief-prompten-voor-teams/)) zijn individuele skills. Contextbeheer is de vaardigheid die AI-gebruik schaalbaar maakt binnen een organisatie.
### Van individueel naar team
Wanneer één medewerker een goed contextdocument maakt, kan het hele team daarvan profiteren. Een huisstijldocument dat iedereen meestuurt. Een klantprofiel dat het hele accountteam gebruikt. Procesbeschrijvingen die nieuwe medewerkers direct aan AI kunnen voeden. Lees hoe je dit opschaalt naar een volledige [AI-kennisbank](/kennisbank/ai-kennisbank-opbouwen/).
### Van incidenteel naar structureel
Zonder AI-werkomgeving is elk AI-gebruik een losstaand experiment. Met een werkomgeving wordt AI een structureel onderdeel van het werkproces. Medewerkers hoeven niet elke keer opnieuw het wiel uit te vinden.
### Het ROI-argument
De grootste tijdsbesparing zit niet in het genereren van antwoorden (dat doet AI in seconden). De tijdsbesparing zit in het *niet hoeven herschrijven* van onbruikbare output. Medewerkers met goede context besteden minder tijd aan het corrigeren van generieke resultaten en meer tijd aan werk dat er toe doet.
Organisaties met een gestructureerde AI-aanpak melden consistent minder tijd kwijt te zijn aan het herschrijven van onbruikbare output.
Organisaties die contextbeheer serieus nemen, zien een verschuiving: van "AI werkt niet voor ons" naar "AI begrijpt hoe wij werken."
## Observeerbaar gedrag per niveau
Hoe herken je of medewerkers contextbeheer beheersen? Onderstaande tabel beschrijft concreet gedrag per niveau:
| | Starter | Basis | Vaardig |
|---|---------|-------|---------|
| **Contextgebruik** | Geeft minimale of geen context mee aan AI | Stuurt relevante contextdocumenten mee bij complexe taken | Beheert project-brede context, houdt documenten actueel |
| **AI-werkomgeving** | Slaat output sporadisch op, geen vaste structuur | Heeft een werkende mappenstructuur (3 mappen) op eigen systeem | Onderhoudt gedeelde AI-werkomgeving voor het team |
| **Herbruikbaarheid** | Begint elke AI-interactie vanaf nul | Heeft minimaal 1 herbruikbaar contextdocument, combineert dit met vaste prompts | Bouwt en onderhoudt templates die collega's kunnen gebruiken |
| **Efficiëntie** | Besteedt veel tijd aan het corrigeren van generieke output | Krijgt in eerste instantie bruikbare output door goede context | Ervaart merkbare tijdsbesparing, kan dit kwantificeren |
**Hoe je dit meet:**
- Starter: intake-assessment, medewerker beschrijft hoe hij/zij nu AI gebruikt
- Basis: na de [AI Skills Basistraining](/training/microsoft-copilot-basis-training/) (portfolio-opdracht: werkende AI-werkomgeving met minimaal 1 contextdocument)
- Vaardig: na de [AI Werkproces Training](/training/ai-werkproces/) en certificering
## Volgende stap: het complete framework
Je hebt nu de drie AI-vaardigheden verkend: [AI begrijpen](/kennisbank/ai-begrip-hallucinaties/), [effectief prompten](/kennisbank/effectief-prompten-voor-teams/), en contextbeheer. Samen vormen ze het framework waarmee je medewerkers structureel leert werken met AI.
Ga terug naar het overzicht voor het complete plaatje: **[De 3 AI-vaardigheden die je organisatie nodig heeft](/kennisbank/drie-essentiele-ai-skills/)**
## Effectief Prompten: Van vage opdracht naar bruikbaar resultaat
> Waarom 'slechte prompts' geen luiheid zijn maar een communicatieprobleem. Leer de bouwstenen, iteratietechnieken en observeerbaar gedrag per niveau.
**Auteur:** Robert Vos · **Datum:** 2026-02-02
**URL:** https://copilot-academy.nl/kennisbank/effectief-prompten-voor-teams/
## Waarom "slechte prompts" geen luiheid zijn
Een medewerker typt in Copilot: "Maak een samenvatting van dit rapport." Het resultaat is generiek, te lang en mist de kern. De medewerker concludeert: "AI werkt niet." Herkenbaar?
Het probleem is geen luiheid en geen gebrek aan talent. Het probleem is dat prompten een **communicatievaardigheid** is die niemand heeft geleerd. We verwachten van medewerkers dat ze effectief communiceren met een tool die ze niet begrijpen, in een formaat dat ze nooit eerder hebben gebruikt.
Geef een nieuwe collega de opdracht "Maak een samenvatting" en je krijgt terug: van welk rapport? Voor wie? Hoe lang? Welke onderdelen zijn belangrijk? AI stelt die vragen niet. Het raadt en levert generieke output.
De oplossing is geen promptverzameling die medewerkers kopiëren en plakken. De oplossing is medewerkers leren *hoe* ze communiceren met AI. Dat is een vaardigheid die je kunt trainen en verbeteren.
## De 4 bouwstenen van een effectieve prompt
In onze trainingen gebruiken we het **TAAK/CONTEXT/ROL/FORMAT framework** (TCRF). Vier bouwstenen die samen een heldere instructie vormen:
### 1. TAAK: Wat moet AI doen?
Begin met een werkwoord. Wees specifiek over het eindresultaat.
- **Vaag:** "Schrijf iets over het project"
- **Specifiek:** "Schrijf een voortgangsrapportage van maximaal 300 woorden voor het MT over Project Atlas"
### 2. CONTEXT: Welke achtergrond is relevant?
AI weet niets over jouw situatie. Geef de informatie mee die een collega ook nodig zou hebben.
- **Zonder context:** "Schrijf een e-mail aan een klant"
- **Met context:** "Schrijf een e-mail aan Marieke de Vries (HR-manager bij BNG Bank). Vorige week deden we een pilot met 15 deelnemers, score 4.8/5. Doel: follow-up plannen."
### 3. ROL: Welk perspectief moet AI aannemen?
Door een rol te geven, stuur je de toon, het detailniveau en de expertise van de output.
- **Zonder rol:** "Geef feedback op dit rapport"
- **Met rol:** "Je bent een senior redacteur met ervaring in zakelijke communicatie. Geef feedback op helderheid, structuur en overtuigingskracht."
### 4. FORMAT: Hoe moet het resultaat eruitzien?
Geef aan welke vorm je verwacht. Dit voorkomt dat je na het genereren alsnog moet herformatteren.
- **Zonder format:** "Geef tips voor de vergadering"
- **Met format:** "Geef 5 tips als genummerde lijst. Per tip: titel in 3-5 woorden, gevolgd door uitleg in 1 zin."
De uitgebreide uitleg per bouwsteen met meer voorbeelden vind je in onze [AI Skills Basistraining](/training/microsoft-copilot-basis-training/).
## Twee voorbeelden uit de HR/L&D-praktijk
### Voorbeeld 1: Trainingsvoorstel schrijven
**Zwakke prompt:**
> Schrijf een voorstel voor een AI-training.
**Resultaat:** een generiek document dat niet past bij de organisatie, zonder budget, zonder doelgroep, zonder meetbare doelen.
**Sterke prompt:**
> **TAAK:** Schrijf een voorstel van 1 A4 voor een AI-vaardigheidstraining voor onze afdeling HR (12 medewerkers).
>
> **CONTEXT:** We gebruiken Microsoft 365 met Copilot-licenties sinds 3 maanden. Adoptie is laag: 4 van de 12 gebruiken Copilot actief. Management wil dat het hele team binnen Q2 op basisniveau zit. Budget: €5.000.
>
> **ROL:** Je bent een L&D-adviseur met ervaring in digitale transformatie bij middelgrote organisaties.
>
> **FORMAT:** Structuur: aanleiding (3 zinnen), doelstelling (SMART), aanpak (3 stappen), investering, verwacht resultaat. Toon: zakelijk, overtuigend voor MT.
**Resultaat:** een gericht voorstel dat direct naar het MT kan, met concrete cijfers en een implementatieplan.
### Voorbeeld 2: Evaluatieformulier ontwerpen
**Zwakke prompt:**
> Maak een evaluatieformulier voor een training.
**Resultaat:** een standaard smiley-formulier met vragen als "Hoe tevreden bent u?". Weinig bruikbaar voor verbetering.
**Sterke prompt:**
> **TAAK:** Ontwerp een evaluatieformulier dat zowel tevredenheid als leereffect meet na een AI-vaardigheidstraining.
>
> **CONTEXT:** Deelnemers zijn kenniswerkers (HBO+), training duurt 1 dag, focus op prompten en AI-werkomgeving inrichten. We willen meten of deelnemers de vaardigheden in de praktijk toepassen.
>
> **ROL:** Je bent een learning consultant gespecialiseerd in Kirkpatrick's evaluatiemodel.
>
> **FORMAT:** 10 vragen: 4 over reactie (5-puntsschaal), 3 over leren (open + gesloten), 3 over gedragsintentie. Eindig met 1 open vraag. Formuleer in "je"-vorm.
**Resultaat:** een professioneel formulier dat onderscheid maakt tussen tevredenheid en daadwerkelijk leereffect.
## Het gesprek na de eerste prompt
Een veelgemaakte fout: na het eerste resultaat opgeven of het zonder aanpassing overnemen. Effectief prompten is iteratief. Je werkt in een gesprek met AI.
### Hoe iteratie werkt
1. **Stuur je startprompt** (met de 4 bouwstenen)
2. **Beoordeel het resultaat**: wat is goed, wat mist?
3. **Geef gerichte feedback**: niet "maak het beter" maar specifiek wat je wilt veranderen
4. **Herhaal** tot het resultaat bruikbaar is
### Feedback die werkt
| In plaats van... | Zeg... |
|-----------------|--------|
| "Dit is niet goed" | "De toon is te formeel voor deze doelgroep. Maak het persoonlijker, gebruik 'je' in plaats van 'u'." |
| "Maak het beter" | "Voeg concrete voorbeelden toe bij punt 2 en 4. Maak de conclusie 50% korter." |
| "Nog een keer" | "Herschrijf de inleiding vanuit het perspectief van de manager, niet de medewerker." |
### Wanneer opnieuw beginnen?
Soms is itereren niet genoeg. Begin een nieuw gesprek wanneer:
- De richting fundamenteel verkeerd is (AI heeft de opdracht anders geïnterpreteerd)
- Je halverwege van aanpak wilt veranderen
- Het gesprek te lang wordt en AI [context verliest](/kennisbank/context-management-ai-werkomgeving/)
**Vuistregel:** 2-3 iteraties is normaal. Na 5 iteraties zonder verbetering: herformuleer je startprompt of begin opnieuw.
## Complexe taken opdelen
AI presteert beter op gerichte taken dan op brede opdrachten. Een megatprompt van 500 woorden die 10 dingen tegelijk vraagt, levert bijna altijd matig resultaat.
### De 3-stappenmethode
**Stap 1: Laat AI de structuur bepalen**
> "Ik wil een onboardingprogramma voor nieuwe medewerkers schrijven. Welke onderdelen moet dit programma bevatten? Geef een inhoudsopgave."
**Stap 2: Werk per onderdeel uit**
> "Werk onderdeel 3 'Eerste werkweek' uit. Context: [specifieke informatie]. Format: dagprogramma met activiteiten en verantwoordelijke personen."
**Stap 3: Combineer en verfijn**
> "Hier zijn de uitgewerkte onderdelen [plak ze samen]. Maak de overgangen vloeiend, verwijder overlap en zorg dat de toon consistent is."
Je krijgt beter resultaat én meer controle over het eindproduct.
## Wat managers moeten zien
Als manager of L&D-professional hoef je niet elke prompt te lezen. Maar je kunt wel herkennen of medewerkers de vaardigheid ontwikkelen:
**Signalen van groei:**
- Medewerker besteedt iets meer tijd aan de prompt, maar krijgt sneller bruikbaar resultaat
- Output hoeft minder handmatig te worden aangepast
- Medewerker kan uitleggen *waarom* een prompt goed of slecht werkte
- Medewerker deelt werkende prompts met collega's
**Signalen van stagnatie:**
- Medewerker typt steeds korte, vage opdrachten
- Output wordt standaard volledig herschreven
- Medewerker zegt "AI werkt niet voor mijn werk"
- Geen opgeslagen prompts, elke keer opnieuw beginnen
## Observeerbaar gedrag per niveau
| | Starter | Basis | Vaardig |
|---|---------|-------|---------|
| **Promptkwaliteit** | Schrijft eenvoudige, korte instructies | Gebruikt alle 4 bouwstenen (TCRF) in startprompts | Maakt herbruikbare prompttemplates voor terugkerende taken |
| **Iteratie** | Accepteert eerste output of geeft op | Verfijnt output met minimaal 2 gerichte follow-ups | Lost outputproblemen methodisch op, weet wanneer opnieuw te beginnen |
| **Werkwijze** | Typt prompts direct in de chatinterface | Schrijft startprompts extern (in document) voordat ze worden ingevoerd | Beheert een promptbibliotheek, optimaliseert prompts voor specifieke use cases |
| **Kennisdeling** | Gebruikt AI individueel, deelt geen aanpak | Slaat werkende prompts op voor eigen hergebruik | Deelt prompts en best practices met het team |
**Hoe je dit meet:**
- Starter: intake-assessment of eerste observatie
- Basis: na de [AI Skills Basistraining](/training/microsoft-copilot-basis-training/) (portfolio-opdracht: ontwikkelde startprompt met alle 4 bouwstenen, getest en verfijnd)
- Vaardig: na de [AI Werkproces Training voor je kenniswerk](/training/ai-werkproces/) en certificering
## De valkuil van promptverzamelingen
Een laatste waarschuwing. Het is verleidelijk om medewerkers een lijst met "de beste prompts" te geven en te denken dat het probleem is opgelost. Dat werkt niet.
Promptverzamelingen zijn nuttig als referentie, maar ze vervangen de vaardigheid niet. Een gekopieerde prompt werkt zolang de situatie precies overeenkomt. Zodra de context verandert (andere klant, ander document, andere toon), moet de medewerker de prompt kunnen *aanpassen*. Dat vereist begrip van de bouwstenen, niet het kopiëren van voorbeelden.
Je kunt iemand een recept geven, en dat recept zal werken. Maar een kok die de principes begrijpt (waarom je iets bakt, wat smaakbalans is) kan improviseren wanneer een ingredient ontbreekt. Dat is het verschil tussen een promptverzameling en promptvaardigheid.
Investeer daarom in de vaardigheid, niet alleen in de verzameling.
## Volgende stap: van prompt naar context
Je weet nu hoe je effectieve instructies geeft aan AI. Maar de kwaliteit van je output wordt niet alleen bepaald door je prompt. Het wordt bepaald door de *informatie* die AI tot zijn beschikking heeft.
Lees verder: [Contextbeheer: Hoe je AI leert je organisatie te begrijpen](/kennisbank/context-management-ai-werkomgeving/)
Of ga terug naar het overzicht: [De 3 AI-vaardigheden die je organisatie nodig heeft](/kennisbank/drie-essentiele-ai-skills/)
## De 3 AI-vaardigheden die je organisatie nodig heeft
> Waarom AI-licenties zonder vaardigheden niet werken. Ontdek de drie skills (AI begrip, effectief prompten en contextbeheer) en hoe je ze meetbaar maakt.
**Auteur:** Robert Vos · **Datum:** 2026-01-10
**URL:** https://copilot-academy.nl/kennisbank/drie-essentiele-ai-skills/
## Waarom "gewoon uitproberen" niet werkt
Je organisatie heeft geïnvesteerd in AI-licenties. Microsoft 365 Copilot is uitgerold, de technologie staat klaar. Maar na drie maanden blijkt: een deel van het team gebruikt het dagelijks, een groter deel heeft het na twee weken laten liggen.
Dit patroon zien we bij vrijwel elke organisatie die we begeleiden. Het probleem is niet de technologie. Het probleem is de aanname dat medewerkers vanzelf leren werken met AI.
Bij organisaties zonder gestructureerde training zien we dat het merendeel van de medewerkers na drie maanden stopt met AI of het alleen voor basistaken gebruikt.
### De teleurstellingscyclus
Het verloopt bijna altijd hetzelfde:
1. Licenties worden uitgedeeld, medewerkers proberen het uit
2. De output is generiek, niet bruikbaar, soms ronduit fout
3. "AI werkt niet voor mijn werk", de licentie blijft ongebruikt
4. Management ziet geen rendement op de investering
De oplossing is niet meer licenties, betere tools of strengere adoptie-KPI's. De oplossing is **vaardigheden**. Medewerkers die weten hoe ze met AI moeten werken, halen er consistent waarde uit. Medewerkers die het niet weten, haken af.
## Drie vaardigheden, niet drie tools
Bij Copilot Academy trainen we medewerkers in drie kernvaardigheden. Niet drie tools, niet drie features, maar drie vaardigheden die werken met elke AI-tool, of dat nu Copilot, ChatGPT of Claude is.
De metafoor die we gebruiken: zie AI als een **hyperintelligente stagiair**. Enorm capabel, snel, en met toegang tot een encyclopedische hoeveelheid kennis. Maar: geen ervaring met jouw organisatie, geen besef van wat belangrijk is, en af en toe een antwoord dat er goed uitziet maar niet klopt.
Om effectief samen te werken met deze stagiair heb je drie dingen nodig:
1. **Begrijpen wat de stagiair kan en niet kan** → AI Begrip
2. **Heldere opdrachten geven** → Effectief Prompten
3. **De stagiair de juiste achtergrondinformatie geven** → Contextbeheer
Deze drie vaardigheden bouwen op elkaar. Je kunt niet goed prompten zonder AI te begrijpen. En je prompts worden pas echt krachtig als je context toevoegt. Daarom behandelen we ze in deze volgorde.
## Skill 1: AI Begrip
De eerste vaardigheid is begrijpen hoe AI werkt. Niet technisch, maar functioneel. Medewerkers die dit begrijpen, weten wanneer ze AI kunnen vertrouwen en wanneer ze extra moeten controleren.
Dit omvat:
- Hoe taalmodellen antwoorden genereren (voorspelling, geen begrip)
- Waarom AI hallucineert en hoe je dat herkent
- De VAK-check: drie vragen voor elke AI-output
- Het stoplichtmodel: wanneer snel scannen, wanneer grondig verifiëren
Zonder AI-begrip ontstaan twee risico's: medewerkers die alles blind overnemen, of medewerkers die na één fout AI compleet afwijzen. Beide zijn kostbaar.
**Lees het volledige artikel:** [AI Begrip: Waarom medewerkers moeten snappen hoe AI werkt](/kennisbank/ai-begrip-hallucinaties/)
## Skill 2: Effectief Prompten
De tweede vaardigheid is het geven van gestructureerde instructies. Het verschil tussen een vage opdracht en een bruikbaar resultaat zit vrijwel altijd in de kwaliteit van de prompt.
Dit omvat:
- De 4 bouwstenen: Taak, Context, Rol, Format (het TCRF-framework)
- Iteratief werken: het gesprek ná de eerste prompt
- Complexe taken opdelen in gerichte stappen
- De valkuil van promptverzamelingen (begrip > kopiëren)
Prompten is geen technische skill, het is een communicatievaardigheid. En net als elke communicatievaardigheid kun je het leren, oefenen en verbeteren.
**Lees het volledige artikel:** [Effectief Prompten: Van vage opdracht naar bruikbaar resultaat](/kennisbank/effectief-prompten-voor-teams/)
## Skill 3: Contextbeheer
De derde vaardigheid, en de meest onderschatte, is contextbeheer. AI weet niets over je organisatie, je klanten, je processen. Elke chat begint met een blanco lei.
Dit omvat:
- Wat contextdocumenten zijn en hoe je ze maakt
- De AI-werkomgeving: drie mappen die je AI-werk structureren
- Van generieke naar organisatie-specifieke output
- Herbruikbare templates: prompt + context = consistent resultaat
Contextbeheer is de vaardigheid die AI-gebruik schaalbaar maakt. Eén goed contextdocument kan door het hele team worden gebruikt. Dat is het verschil tussen individueel experimenteren en organisatiebrede adoptie.
**Lees het volledige artikel:** [Contextbeheer: Hoe je AI leert je organisatie te begrijpen](/kennisbank/context-management-ai-werkomgeving/)
## Hoe je AI-vaardigheden meet
Als HR- of L&D-professional wil je niet alleen weten *of* medewerkers met AI werken, maar ook *hoe goed*. Wij werken met drie niveaus die aansluiten bij observeerbaar gedrag op de werkvloer:
### Overzicht per niveau
| Vaardigheid | Starter | Basis | Vaardig |
|-------------|---------|-------|---------|
| **AI Begrip** | Weet dat AI fouten maakt, controleert incidenteel | Past VAK-check toe, schat taken bewust in | Voorspelt AI-beperkingen, ontwerpt verificatieprocessen |
| **Effectief Prompten** | Schrijft korte, vage instructies | Gebruikt alle 4 TCRF-bouwstenen, itereert | Maakt herbruikbare templates, deelt met team |
| **Contextbeheer** | Geeft minimale context, geen structuur | Heeft AI-werkomgeving met contextdocumenten | Beheert teamcontext, ervaart meetbare tijdsbesparing |
### Wat elk niveau betekent
**Starter**: experimenteert ad-hoc met AI
> "Ik kan AI inzetten voor eenvoudige taken zoals samenvatten en concepten schrijven, waarbij ik de output controleer."
**Basis**: past AI gestructureerd toe op eigen werk
> "Ik schrijf gestructureerde prompts, controleer output systematisch en werk met een georganiseerde AI-omgeving."
**Vaardig**: ontwerpt herbruikbare AI-werkprocessen
> "Ik ontwerp AI-workflows voor mezelf en mijn team. Ik weet waar AI wel en niet werkt, en kan mijn aanpak overdragen."
### Hoe je meet
Per vaardigheid beschrijven we **observeerbaar gedrag**: concreet en toetsbaar. Geen abstracte competenties, maar dingen die je op de werkvloer kunt waarnemen:
- Controleert de medewerker feiten voordat AI-output wordt verstuurd?
- Schrijft de medewerker prompts extern voor in een document?
- Heeft de medewerker een werkende AI-werkomgeving met contextdocumenten?
De gedetailleerde gedragstabellen vind je in elk van de drie verdiepingsartikelen.
## Van inzicht naar implementatie
Je weet nu welke drie vaardigheden het verschil maken. De vraag is: hoe breng je die bij je team?
### Onze aanpak
Bij Copilot Academy werken we met een gestructureerd programma dat de drie vaardigheden opbouwt in logische volgorde:
1. AI Begrip opbouwen: begrijp de mogelijkheden en beperkingen
2. Promptvaardigheden ontwikkelen: leer communiceren met AI
3. AI-werkomgeving inrichten: maak AI structureel onderdeel van het werk
Elke stap bouwt voort op de vorige. En elke stap levert meetbaar resultaat: van observeerbaar gedrag tot concrete tijdsbesparing.
Na het volledige programma zien we dat deelnemers AI structureel blijven gebruiken en de geleerde vaardigheden toepassen in hun dagelijkse werk.
Wil je weten hoe dit er voor jouw organisatie uit kan zien? Bekijk het [AI Skills Programma](/ai-skills-programma/) of [plan een gesprek](/contact/) met een van onze trainers.